 Jindřich's blog
Jindřich's blog


Highlights from Machine Translation and Multilinguality in July 2022
Here is my monthly summary of what I found worth reading on arXiv in the past month.
A preprint from JHU studies zero-shot cross-lingual transfer using pretrained multilingual representation and comes to the conclusion that it is an under-specified optimization problem. In other words, with a multilingual representation model, there are potentially many solutions that are good for the source language, but only some of them are good for the target language. In practice, the solution is probably proper training in the source language and few-shot training in the target language. (After all, a zero-shot setup is always more of theoretical interest than practical. Collecting a dozen of labeled examples should always be possible.)
Sockey 3, an MT toolkit by Amazon is out and is written in PyTorch (the previous versions were based on MXNet, which I think discouraged many potential users). The pre-print claims to be as fast and as good as Fairseq and better than OpenNMT — unfortunately, there is no comparison with Marian.
Google Brain introduced N-grammer simple modification of the Transformer architecture: it combines unigram and bigram embeddings as the input. A proper bigram vocabulary would of course be enormous (e.g., a pretty standard 32k vocabulary around 1M bigrams). The trick they go around this is using a constant-sized hash table for storing the bigram embeddings (with many unresolved conflicts). It seems a bit like a cross-over between subword models and what people do in character-level models (such as Charformer). The results look good, but the paper only uses English. Also, I wonder if it in fact isn’t mostly compensation for inappropriate tokenization.
A preprint from DeepMind presents a method called MAD, which seems to me as the first reinforcement learning for MT that seems that might work well enough, such that I would consider using it in practice. I did not understand all the details, but my layman’s interpretation of what they do is, that it looks like the REINFORCE algorithm with a clever baseline and clever weighting, so the variance of the training signal remains low.
A preprint from the University of Washing and CMU in
Pittsburgh presents exciting experiments
where they formulate zero-shot machine translation as a communication game. The
baseline is doing iterated backtranslation starting from pre-trained
mBART (see my also comments in MT Weekly
28). In the communication game setup, they
add an intermediate step: they fine-tune the model to do image captioning in
English, and teach the model to play the image selection game, i.e., based on a
sentence, it should choose the correct image. It either translates the English
caption into the target language or generates the caption in the target
language and then based on the encoder, it is supposed to recognize to what
image the caption belongs. Figure 1 of the paper shows, how the training setup
looks like 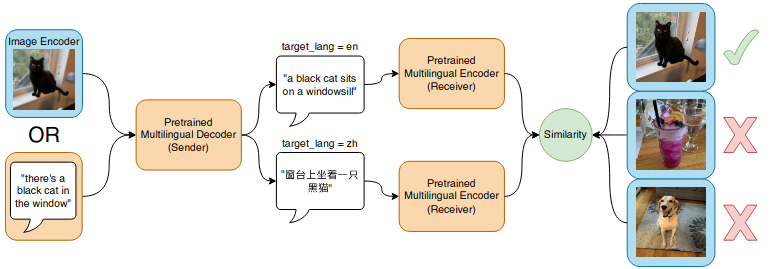
When combined with standard iterated back-translation, it leads to a huge translation quality gain in high-resource languages (where doing zero-shot translation does not make much sense) and modest improvements in low-resourced ones.
Share the post
@misc{libovicky2022blog0803,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Highlights from Machine Translation and Multilinguality in July 2022",
year = "2022",
month = aug,
url = "https://jlibovicky.github.io/2022/08/03/MTML-July",
note = "Online, Accessed: 05.06. 2026"
}