 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 93: Notes from EMNLP 2021
Another big NLP conference is over and here are my notes about the paper that I liked the most. My general impression was sort of similar to what I got from ACL this year. It seems to me that the field is progressing towards some behavioral understanding of what the neural models do, which allows doing some cool tricks that it was hardly possible to think of, only a few years ago. Excellent examples are tricks with adapters or non-parametric methods for language modeling and MT. All of it is sort of procedural knowledge – recipes on how to make things work well – surprisingly, it does not help for making NLP methods more explainable, and work on model interpretability does seem to help much either (although most of the results are really interesting).
ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora
ERNIE-M is currently probably the best multilingual sentence representation model available and comes from Chinese Baidu. It lacks the elegance of models like mBERT and XLM-R that somehow become cross-lingual without any cross-lingual training signal, but who care if it works well. ERNIE-M needs parallel data for pre-training. And if they do not exist, it generates pseudo-parallel data using back-translation. Clever masking during pre-training forces the model to represent different languages similarly.
All Bark and No Bite: Rogue Dimensions in Transformer Language Models Obscure Representational Quality
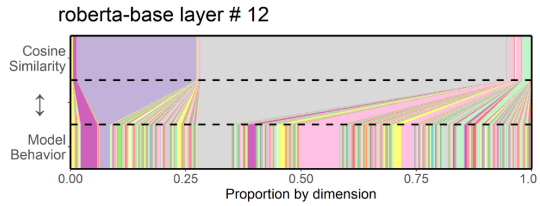
This paper presents an interesting view on comparing embeddings with cosine similarity. The paper reveals that with most embeddings, only a few dimensions contribute significantly to the cosine distance and most of them are ignored, even though they also carry important information. Long story short: standardization that gets the dimensions approximately equal weight improves the similarity measuring.
It is nicely illustrated in Figure 1 of the paper that compares the importance of dimensions for model behavior and for cosine similarity.
The World of an Octopus: How Reporting Bias Influences a Language Model’s Perception of Color
The paper presents a dataset for assessing reporting bias in language models. People communicate only what needs to be communicated and usually do not say obvious things. Language models only learn from something that someone communicated, which suggests they only have a limited chance to learn obvious things. For instance, Bender and Koller (2020) view this problem so seriously that they conclude based on a thought experiment (with an octopus) that learning really good language models only from text is impossible. This EMNLP paper assess that empirically. It creates a dataset that tries to quantify how serious this problem is. The challenge set measures if the language models know the usual color of objects. E.g., a banana is usually yellow, but the textual evidence says that if there is a color next to banana, it is typically green. There is no need to say banana is yellow. Experiments show that language models tend to capture more what is in the text than the reality.
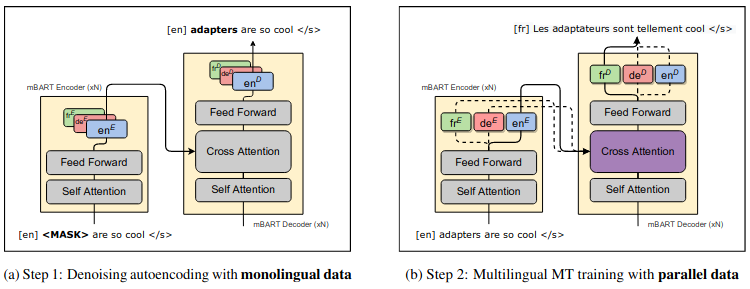
Multilingual Unsupervised Neural Machine Translation with Denoising Adapters
Finetuning mBART for machine translation has the following problem: Although it is pre-trained very multilingually, during finetuning it forgets the languages it was not finetuned for. The paper presents a solution: learn language-specific adapters in mBART already during pre-training, during finetuning, re-learn only cross-attention. Then, if they use respective language-specific adapters, it works zero-shot and iterating back-translation can take care of the rest. Figure 3 of the paper actually says everything one needs to know.
Boosting Cross-Lingual Transfer via Self-Learning with Uncertainty Estimation
The paper presents a recipe for how to do cross-lingual model transfer when we only have monolingual data in the target language. They start with zero-shot transfer: train the model in the source language, generate pseudo-labeled corpus in the target language, and use good uncertainty estimation (I did not know any of the methods that they use, but they look cool) to decide what pseudo-labeled examples should be kept. These pseudo-label examples are then used in the next iteration of the training. This is very similar to UXLA, a cross-lingual data augmentation method presented at ACL which used an ensemble of zero-shot models instead of the uncertainty estimation.
Robust Open-Vocabulary Translation from Visual Text Representations
In this paper, they: 1. Render text as an image, 2. Train a CNN followed by a sequence-to-sequence transformer to do machine translation. Although it sounds crazy, it works nearly as good as normal MT and seems to be much robust towards source-side noise. Looks cool, but I would be keen to see a comparison with BPE dropout and other methods that can help make the translation more robust.
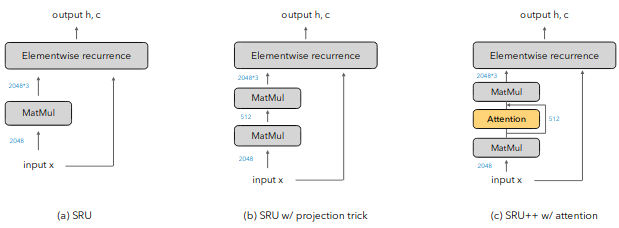
When attention meets fast recurrence
Very cool new recurrent architecture. The authors take Simple Recurrent Unit, which is simple, extremely fast, but pretty lame, add attention in between and get something that is not that simple, still very fast and comparable with Transformer LMs. I can very well imagine, this as a future of decoders in machine translation. The architecture of the cell is nicely explained in Figure 2 of the paper:
Learning Kernel-Smoothed Machine Translation with Retrieved Examples
This is based on kNN MT. After an NMT model is trained, they create a database matching hidden states with output words which are retrieved at inference time and mixed with the standard output distribution. Unlike the previous kNN MT, this dynamically decides if it should use the standard output distribution or what was retrieved from the database.
Contrastive Conditioning for Assessing Disambiguation in MT: A Case Study of Distilled Bias
Main message: Knowledge distillation makes biases worse. But the paper also presents a new cool method for measuring gender bias: contrastive conditioning that does not require reference translation. On the other hand, we need to understand the source language. It works as follows: 1. Keep the source as it is and get a translation, 2. Change source by adding disambiguation words (e.g., male or female) and measure with which source sentence the translation gets a higher score. Figure 1 of the paper:

Clustering Monolingual Vocabularies to Improve Cross-Lingual Generalization
This is a workshop paper, but totally cool. Before pre-training an mBERT-like model, they learn cross-lingual embeddings and make cross-lingual clusters of monolingual embeddings. The clusters are their input vocabulary rather than normal token IDs. They do only 9 languages and have limited computation capacity, but the results seem very promising. (This confirms my suspicion that the main problem of pre-trained models is lexical cross-linguality.)
Share the post
@misc{libovicky2021blog1117,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 93: Notes from EMNLP 2021",
year = "2021",
month = nov,
url = "https://jlibovicky.github.io/2021/11/17/MT-Weekly-Notes-from-EMNLP-2021",
note = "Online, Accessed: 05.06. 2026"
}