 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 87: Notes from ACL 2021
The story of the science fiction novel Roadside Picnic by Arkady and Boris Strugatsky (mostly known via Tarkovsky’s 1979 film Stalker) takes place after an extraterrestrial event called the Visitation. Some aliens stopped by, made a roadside picnic, and left behind plenty of weird and dangerous objects having features that contemporary science cannot explain. Although the UN tries to prevent people from entering the visitation zones before everything gets fully explored and explained, objects from the zone are traded on a black market. Soon, the semi-legal discoveries from the zone find use in the industry without anyone having a good understanding of how the mysterious objects and materials work.
I got a very similar feeling from this year’s ACL as from this novel. In my not so elaborated analogy, the advent of deep learning is the extraterrestrial event, of course. Now, years after, we try to do now is make sense of what happened, some try to figure out if it is not dangerous and some try to make some money out of it. No wonder that the best papers at the conference, both those that the organizers recognized as the best ones and those that I personally liked the most, did not push the state-of-the-art by a large margin but brought some interesting insights and reflected the inventions of previous years.
What changed my beliefs
Few papers changed what I previously thought were the solid truths of NLP I would not hesitate to write in a textbook for the next 5 years.
-
Standard word embeddings are not best for lexical semantics anymore, it is better to extract them from BERT. (See below.)
-
Reranking of MT model outputs can bring much bigger gains than I thought.
-
Multilingual representations are cool, but there are plenty of potentially cross-lingual tasks where current cross-lingual models spectacularly fail. (See below.)
Some interesting papers
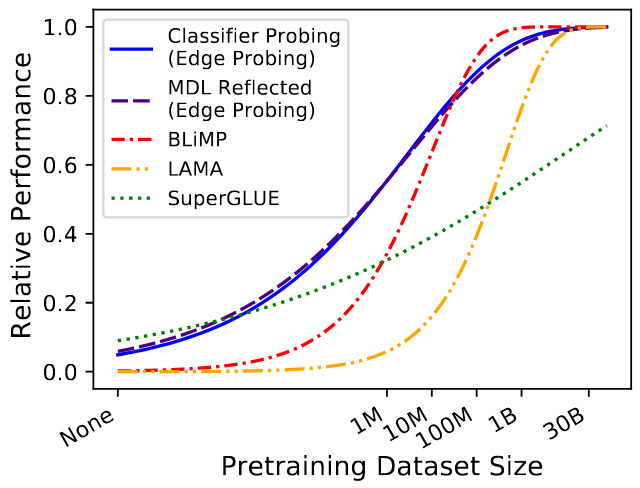
When Do You Need Billions of Words of Pretraining Data?
They train a dozen of RoBERTas on different data sizes. For syntactic tasks, ~10M words pretraining is enough, for semantic tasks ~100M words, for common sense (here, Winograd) billions of words are necessary (no matter how we probe). For SuperGLUE not even 30B is enough…
Figure 1 from the paper:
Standard beam search maximizes the probability of the hypothesis set, which is by chance the determinant of a diagonal matrix with candidate probabilities in each step (this is no miracle, it is a product of the hypotheses probabilities and a determinant of a diagonal matrix is the product of the diagonal, but still what a cool observation!). And what if off-diagonal entries encode the similarity of the hypothesis? Then the algorithm will also optimize the diversity of the samples.
LexFit: Lexical Fine-Tuning of Pretrained Language Models
Pre-trained LMs already contain more lexical knowledge than static word embeddings. A small finetuning push from WordNet is enough to expose the lexical knowledge and they get much better results than FastText. The provocative conclusion is that we might not need the traditional word embeddings anymore. If we want to get high-quality static word embeddings, we can get them from BERT-like models (but how to do it without WordNet)?
The paper introduces a methodology of measuring the sensitivity of models to sentence reordering and they found out that NLI is surprisingly permutation invariant, but the invariance indeed depends on how similar it is to the original order. This is quite a cool extrinsic measure of how contextualized a model is, by sort measuring its distance from bag-of-words models.
Exposing the limits of Zero-shot Cross-lingual Hate Speech Detection
The success of cross-lingual hate speech detection depends on the types of hate speech. For instance, hate speech against immigrants is easier to detect cross-lingually than hate speech against women because the language is less idiomatic in the first case. But in both cases, the results are pretty poor.
X-Fact: A New Benchmark Dataset for Multilingual Fact Checking
Dataset for multilingual fact-checking. mBERT works fine within a language, metadata help, Google search helps. But once we do it cross-lingually, it does not work almost at all.
Share the post
@misc{libovicky2021blog0813,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 87: Notes from ACL 2021",
year = "2021",
month = aug,
url = "https://jlibovicky.github.io/2021/08/13/MT-Weekly-Note-from-ACL-2021",
note = "Online, Accessed: 05.06. 2026"
}