 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 74: Architectrues we will hear about in MT
This week, I would like to feature three recent papers with innovations in neural architectures that I think might become important in MT and multilingual NLP during the next year. But of course, I might be wrong, in MT Weekly 27, I self-assuredly claimed that the Reformer architecture will start an era of much larger models than we have now and will turn the attention of the community towards document-level problems and it seems it is not happening.
CANINE: Tokenization-free encoder
Tokenization is one of the major hassles in NLP. Splitting text into words (or other meaningful units) sounds simple, but it gets quite complicated when you go into details. These days, the German parliament discusses the “Infektionschutzgesetz”, which means the infection protection law. It is formally one word, but obviously, it would make very much sense to split such a monster word into three meaningful subwords. Developing rules for segmenting text into meaningful units for every single language would is a hardly feasible task, and statistical heuristics are used instead. They work well but are totally ugly. It would be thus great if we could avoid the hassle and use character directly as input.
On the other hand, it seems that character-level models are difficult to train (see e.g., our EMNLP 2020 paper on character-level MT). The best character-level models are those that manage to squeeze the long character sequence into some latent word-like units. CANINE by Google is one of such models, and also the first pre-trained character-level BERT-like model. First, they use local self-attention on small windows of characters. Then, they shrink the sequence using a 1D convolution. See Figure 1 of the pre-print:
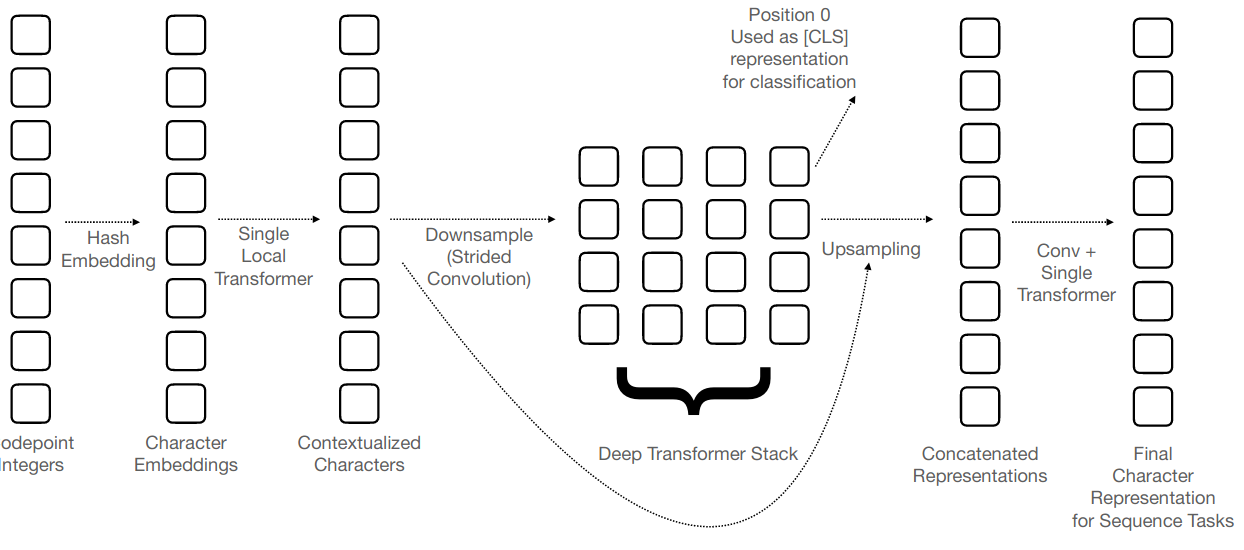
Imagine how beautiful the world will be when all NLP will be character-level working with raw text and no one will care about tokenization anymore!
When Attention Meets Fast Recurrence
The preprint When Attention Meets Fast Recurrence: Training Language Models with Reduced Compute by Tao Lei from February shows how to combine RNN and self-attention to get a fast and very good language model. A simple RNN cell based on something that is really called Simple Recurrent Unit (SRU) is enriched by self-attention and that is it. They call it SRU++. The architecture looks like this (Figure 2 of the paper):
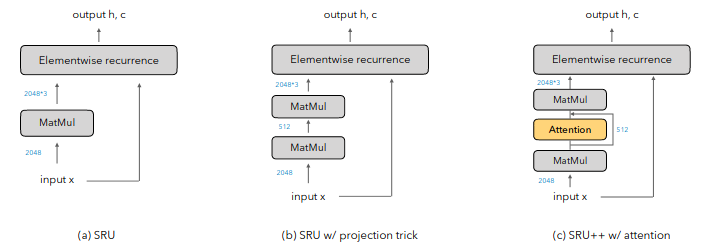
The model can match (or even beat) Transformer XL on perplexity in less than one-fourth of training time (further gains reported in the paper are due to using mixed-precision training, so it is not really a fair comparison), despite Transformer can be heavily parallelized everything and RNN is in principal sequential. My guess is that reason why it learns so fast is that it knows what the left-to-right generation is by design and does have to learn it. We can view it also like that they replace the feed-forward blocks in the Transformer with a recurrent layer.
I am pretty sure, sooner or later this architecture will be used as a decoder in machine translation.
The Perceiver
The Perceiver by DeepMind is a simple, but a clever remake of the standard transformer stack. The paper showcases the architecture only on vision problems. Unlike NLP, in vision, the input is very high-dimensional (thousands of RGB pixels instead of dozens of tokens), so the standard self-attention considering all combinations of all inputs is not tractable. The solution that they propose is: start with a sequence of latent states and use them as queries in cross-attention (i.e., as we do encoder-decoder attention in MT) to the input image, the self-attention is done only within the short sequence of latent states.
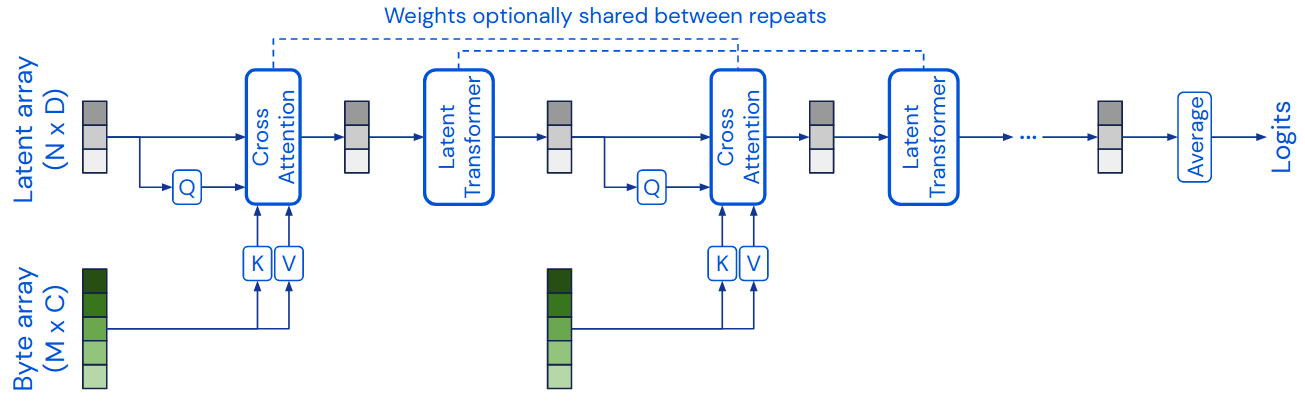
The coolest thing that it is super easy to implement using Huggingface
Transformers (and probably any
implementation of Transformers). Set add_cross_attention to True, the
real input will be provided as encoder_hidden_states and
encoder_attention_mask. What was previously considered the input will be
a sequence of dummy symbols.
I can very well imagine a Perceiver-based encoder that quickly embeds a long input sentence into a 2-times or 3-times shorter sequence of latent states combined with an SRU++ decoder as a big competitor for non-autoregressive MT in terms of speed-quality trade-off.
Share the post
@misc{libovicky2021blog0411,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 74: Architectrues we will hear about in MT",
year = "2021",
month = apr,
url = "https://jlibovicky.github.io/2021/04/11/MT-Weekly-Architecture-we-will-hear-about",
note = "Online, Accessed: 05.06. 2026"
}