 Jindřich's blog
Jindřich's blog


Speeding up arXiv browsing
Staying up to date with the newest NLP work is a tough job, and reading about new research takes a significant amount of my time. For several years, one of my work routines has been skimming over the arXiv digest. I open a few preprints, glance over them, and write some notes into Zotero. Once a month, I write a blog post about what I think was the most interesting, which should force me to understand the papers, at least to the extent I can write a summary.
It sounds great, but it recently started getting out of hand. The number of preprints constantly grows, which brings several problems.
-
Checking the preprints is getting time-consuming.
-
I tend to lose attention, miss papers I would like to read and spend time with those I wish I never saw.
-
I forget what I have read. Sometimes, I do not remember even the papers I blogged about.
Monthly counts of new pre-prints in the Computation & Language category look like this.

As a computer scientist, by training, I tried to code my way out of this problem. Not that I am sure it helps, but it is fun, at least, and it increases the chance that I will not resign on following new papers.
-
I created a command-line app that uses the arXiv API that helps navigate through the abstracts (with highlighted keywords) and, most importantly, tracks what preprints I open and what not.
-
I use the logs to train a Transformer-based classifier to predict whether I will read a paper. Throwing away preprints with a score < 1% reduces the number of abstracts by half.
-
I wrote a script that calls the Zotero API and shows me three random papers I made notes about.
All the stuff I am talking about is available on my GitHub. Fork it and modify it for your needs if you think it might be useful for you too. Following paragraphs, contain some details.
Viewing the arXiv Digest
Initially, I wanted to create a web app for viewing abstracts, but I wanted something quick, so I ended with a CLI interface. This is what it looks like:
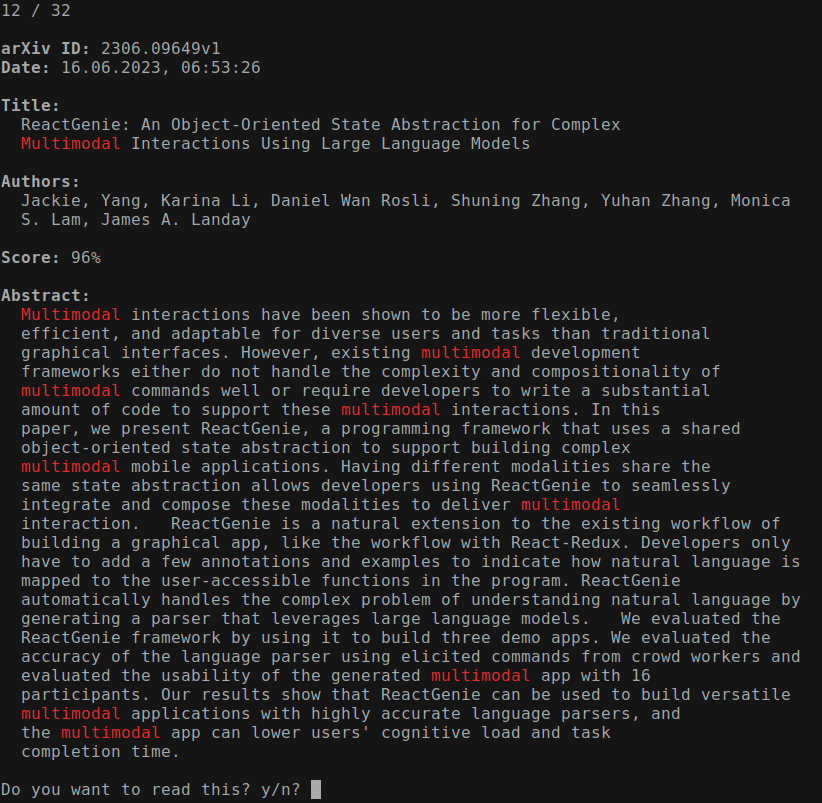
It shows the title, the authors, and the abstract with highlighted (manually
specified) keywords. Pressing y opens the paper in the browser, and pressing
n moves to the next one. I the time stamp of the youngest open preprint and
append to the information about the preprints to JSON files (one JSON per
line). Pre-prints can appear multiple times in the arXiv digest if they get
updated, to when I later process the data, I need to take care about
duplicities. There is a Python package that communicates with the arXiv
API which makes it pretty straightforward.
Predicting what I will read and what I will not
I started collecting training data at the beginning of 2023. Now, in the middle of June, I have 266 positive and 5,828 negative instances, hopefully, a reasonable number of training instances for finetuning a small Transformer model.
As a baseline, I tried logistic regression with TF-IDF features, which resulted in an F1 score of around 33% (with balanced sampling and 100-fold cross-validation). F1 score is not exactly the ideal metric because I am more interested in recall than precision, but I cannot really say how much, so I kept the weights of precision and recall equal.
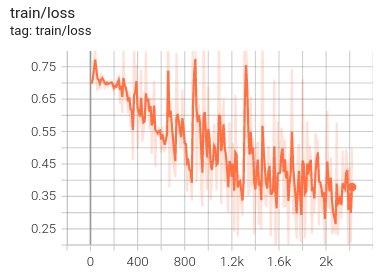
Then I started more serious experiments with DilstillRoBERTa, a small pre-trained Transformer encoder based on RoBERTa (using the PyTorch and the Transformers library). The main issue is that the dataset is very imbalanced, which I am trying to solve by outweighing the positive instances. This is probably why the learning curve in terms of the loss function is quite unstable.
However, the F1 score increases gradually.
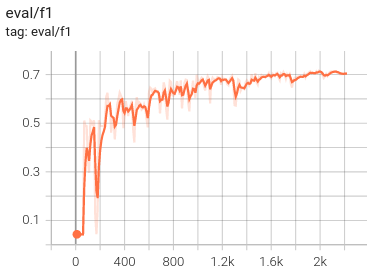
At some stage, I got a small improvement by little of prompt engineering; the
input says Title: before the title and Abstract: in front of the abstract.
But I guess any markup separating the two would do the job. I also experimented
with bigger Transformers, and surprisingly, there was no real difference
between the small and bigger versions of the standard RoBERTa. The F1 score is
still around 70 percent. This might seem like a relatively low number, but it
only would be bad if used the classifier for binary classification. The
worst-scoring papers look like something that I would never open.
| Score | Title |
|---|---|
| 0.992 | XNLI 2.0: Improving XNLI dataset and performance on Cross Lingual Understanding (XLU) |
| 0.992 | ArtGPT-4: Artistic Vision-Language Understanding with Adapter-enhanced MiniGPT-4 |
| 0.992 | Multimodal Learning Without Labeled Multimodal Data: Guarantees and Applications |
| 0.993 | Cross-Lingual Supervision Improves Large Language Models Pre-training |
| 0.993 | mPLM-Sim: Unveiling Better Cross-Lingual Similarity and Transfer in Multilingual Pretrained Language Models |
| 0.993 | Investigating the Translation Performance of a Large Multilingual Language Model: the Case of BLOOM |
| 0.993 | Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis |
| 0.002 | DiscoPrompt: Path Prediction Prompt Tuning for Implicit Discourse Relation Recognition |
| 0.002 | Self-supervised Neural Factor Analysis for Disentangling Utterance-level Speech Representations |
| 0.002 | Fine-grained Early Frequency Attention for Deep Speaker Representation Learning |
| 0.002 | MADNet: Maximizing Addressee Deduction Expectation for Multi-Party Conversation Generation |
| 0.002 | EmotionIC: Emotional Inertia and Contagion-driven Dependency Modelling for Emotion Recognition in Conversation |
| 0.002 | Clinical BERTScore: An Improved Measure of Automatic Speech Recognition Performance in Clinical Settings |
| 0.002 | A Multi-Granularity Matching Attention Network for Query Intent Classification in E-commerce Retrieval |
Given that I am mostly interested in multilingual NLP, machine translation, and language-and-vision modeling, I think the model got that pretty accurately.
By throwing away papers that receive a score lower than 0.01, I can eliminate roughly one-half of the daily arXiv digest while keeping 100% recall. What a time saver! It will only take a decade before the time invested in the development finally pays off.
A Reminder of what I have read
The abstract classifier can perhaps help me with the first two problems caused by too many new papers. The other problem is that there are too many old papers that I have read and forgotten.

I wrote a script that connects to my Zotero library. It downloads all the papers I have there, selects three at random, generates an HTML file with my notes about the paper, and opens it in the browser. There is a Python package for working with the Zotero API, which is very easy to use. The entire script only has 125 lines.
Another advantage is that it helps me realize that I sometimes do not understand my notes, so I need to re-read some parts of the paper and fix the notes. The same happens with the tags I label the papers with.
Share the post
@misc{libovicky2023blog0630,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Speeding up arXiv browsing",
year = "2023",
month = jun,
url = "https://jlibovicky.github.io/2023/06/30/Speeding-up-arXiv-browsing",
note = "Online, Accessed: 05.06. 2026"
}