 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 79: More context in MT
The lack of broader context is one of the main problems in machine translation and in NLP in general. People tried various methods with actually quite mixed results. A recent preprint from Unbabel introduces an unusual quantification of context-awareness and based on that do some training improvements. The title of the paper is Measuring and Increasing Context Usage in Context-Aware Machine Translation and will be presented at ACL 2021.
The paper measures how well informed the model is about the context by computing a quantity that they call conditional cross-mutual information. It sounds complicated, but it is “just” the difference of entropy that the model attributes the reference sentence with and without the context. In other words, how much more probable the correct translation becomes if more context is added to the source sentence. So far, most methods for machine translation evaluation beyond the sentence level focused on particular discourse phenomena via constructing specialized test sets. This method is phenomena-agnostic and dataset-agnostic. It is one hand cool because it is extremely easy to use, on the other hand, it does say much about the particular phenomena.
The main results are shown in Figure 2 of the paper:
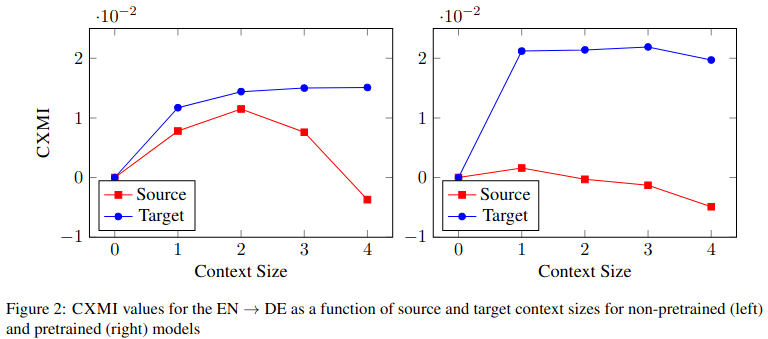
One of the main findings is that source context does not matter much, the target context is much more useful for the translation quality. Another surprise is that more context leads to worse use of the context and to worse translations. One plausible interpretation might be: there is too much information in the context and the training signal is too weak.
The authors offer a solution to the second problem: randomly drop words in the source sentence, such that the model is forced to search for the relevant information in the context. This trick improves not only in the cross-mutual information but the translation quality in general including the special tests for evaluating discourse phenomena in machine translation. In the end, it is nice to see that both source and target context appear to be useful.
This approach – both the measuring context sensitivity and the dropout-based method for forcing the models to notice work with context – fits so well into how neural machine translation is currently conceptualized that I am really surprised that the paper is not from 2017, but from 2021. It makes the paper very cool, on the other hand, it raises a question: why did it take the community so long if it now looks so self-evident?
Share the post
@misc{libovicky2021blog0516,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 79: More context in MT",
year = "2021",
month = may,
url = "https://jlibovicky.github.io/2021/05/16/MT-Weekly-More-Context-to-MT",
note = "Online, Accessed: 05.06. 2026"
}