 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 57: Document-level MT with Context Masking
This week, I am going to discuss the paper “Long-Short Term Masking Transformer: A Simple but Effective Baseline for Document-level Neural Machine Translation” by authors from Alibaba Group. The preprint of the paper appeared a month ago on arXiv and will be presented at this year’s EMNLP.
Including document-level context into machine translation is one of the biggest challenges of current machine translation. It has several reasons. One is the lack of document-level training data, which is partially caused by copyright law. If we want to have replicable results, the training dataset must be public, and most of the texts are under copyright. You cannot be blamed for sharing copyrighted content if it is sentence-split and thoroughly shuffled, such that the original text cannot be reconstructed.
The other reasons are inherent to the models that are currently used. There are relatively few phenomena that depend on distant context and the relevant clues for them are scarcely distributed in the text. As a result, fixing the document-level phenomena ends up having only a little weight in the loss function which does not motivate the model to improve. Because of that, the simple solution: using paragraphs instead of sentences as inputs and outputs of machine translation models only brings a small improvement. Another issue is that the translation quality degrades with the paragraph length because the decoding errors tend to accumulate.
The present-day mantra of deep learning in natural language processing says that getting rid of linguistic or any other assumption about the NLP problems always leads to better results. This is sort of opposite to what people did with statistical methods, which were considered stupid and required the smart linguistic features to work well. Neural networks are considered smart, so they do not need any hints from dumb humans. I believe this way of thinking makes document-level translation difficult. When we want neural networks to find out a solution on their own, they fail because the training signal from context-dependent phenomena is too weak.
This paper starts with a straightforward solution that suffers from the problem I just described. Instead of translating sentence-by-sentence, they translate 4 sentences of the source text into 4 sentences of the target text. The paper comes with a simple and elegant idea of introducing the notion of context into the model: modify the self-attention in the Transformer architecture, such that it explicitly distinguishes between the local (within a sentence) and global context.
In the standard self-attention, every state collects information from all states in the previous layer. The usual interpretation is that every word is collecting information about the context in which it currently appears. In the modified model, there are two types of self-attentions: one that is only allowed to collect information within a sentence and another one that collects information from the entire 4-sentence input.
Given that we trust the small difference in BLEU scores, the results are nicely summarized in the following plot (Figure 2 in the paper):
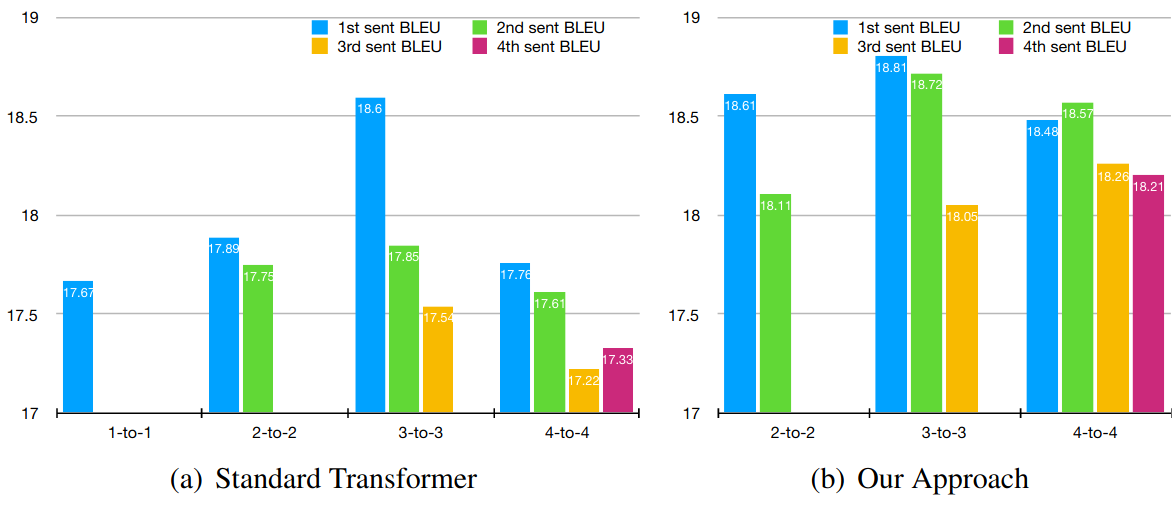
The left half shows the translation quality when they just used 1-4 sentence blocks, the right half shows the results with the improved architecture. The modified architecture slightly improves the first sentence translation quality and to a large extent prevents the quality drop when decoding more sentences. (The second result is great, but I would not expect such a result and I do not have any good intuition why it is so.)
Although the quantitative gain of this method is not overwhelming (especially if you trust the BLEU score similarly as I do), it is a very nice example of how inductive biases can be efficiently added to the current neural models.
Share the post
@misc{libovicky2020blog1101,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 57: Document-level MT with Context Masking",
year = "2020",
month = nov,
url = "https://jlibovicky.github.io/2020/11/01/MT-Weekly-Document-MT-with-Context-Masking",
note = "Online, Accessed: 05.06. 2026"
}