 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 55: Social Polarization Seen through Word Embeddings
This week, I am going to have a closer look at a paper that creatively uses methods for bilingual word embeddings for social media analysis. The paper’s preprint was uploaded last week on arXiv. The title is “We Don’t Speak the Same Language: Interpreting Polarization through Machine Translation,” and most of the authors CMU in Pittsburgh.
The paper’s central assumption is that the polarization of different opinion groups, especially in the USA, went so far that some words have totally different meanings for those groups. For instance, saying that black lives matter has totally different connotations for supporters of the republicans and supporters of the democrats. The goal of the paper is to identify such concepts that have a different meaning for the groups.
The title of the paper misleadingly says that they use machine translation. They do not. They use multilingual embeddings, and they do so in a relatively straightforward way. They train separate word embeddings on texts produced by two different opinion groups. Both the embedding spaces are internally consistent: words with similar meanings have similar vectors. They are not mutually compatible: vectors from one space would end up at totally random places in the other space. Therefore they need to align the vector spaces. Because both groups speak the same language, most words should be aligned to identical ones in the other space. The words that get aligned with some different words are the interesting ones.
Similar to training bilingual embeddings, they take a seed dictionary: a small dictionary of words that we are sure that they have the same meaning in both the languages. In the bilingual case, these are often numbers or proper names. Here, because both groups are supposed to speak the same language, the authors use the grammatical words (pronouns, prepositions, determiners, etc.) as the seed dictionary. Those are the words that certainly have the same meaning for both groups. After aligning the embeddings spaces, most of the words indeed end up aligned with themselves. However, words that both groups use differently end up misaligned.
This is how the misaligned words looked like in a study with comments under CNN and Fox News (Table 4 in the paper):
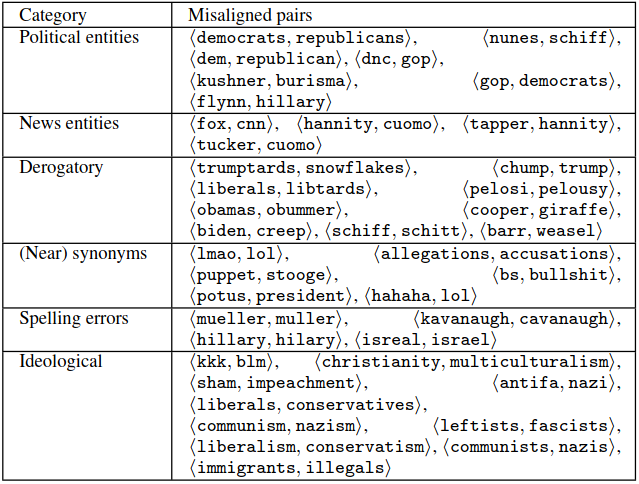
Some of the words that got misaligned are synonyms, but some of them are clearly ideologically motivated. For instance, Fox News commenters use the word “leftist” similarly (in similar contexts and in a similar meaning) as CNN commenters the word “fascist” (very likely as a label for someone with dangerous opinions).
The same method can also be used to compute how similar the meanings are among various groups of commenters (Table 8 of the paper):
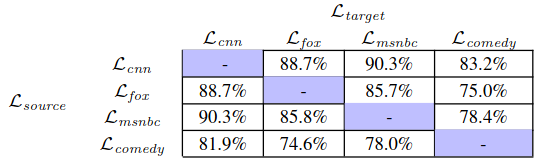
The table shows that comments under comedy video tend to share meanings with how CNN and MSNBC viewers view the world rather than how the Fox News viewers view the world, which is indeed an interesting observation.
Although this paper is not all groundbreaking from the computer science perspective, I totally enjoyed reading it and I am looking forward to social scientists using this method to get some interesting findings.
Share the post
@misc{libovicky2020blog1017,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 55: Social Polarization Seen through Word Embeddings",
year = "2020",
month = oct,
url = "https://jlibovicky.github.io/2020/10/17/MT-Weekly-Polarization-and-Bilignual-Word-Embeddings",
note = "Online, Accessed: 05.06. 2026"
}