 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 54: Nearest Neighbor MT
This week, I will discuss Nearest Neighbor Machine Translation, a paper from this year ICML that takes advantage of overlooked representation learning capabilities of machine translation models.
This paper’s idea is pretty simple and is basically the same as in the previous work on nearest neighbor language models. The paper implicitly argues (or at least I think it does) that the final softmax layer of the MT models is too simplifying and thus pose a sort of information bottleneck, even though the output projection for softmax makes a large portion of the model’s parameters.
To overcome the bottleneck, the paper adds the nearest neighbor search based on the decoder hidden states. With one pass over the training data, they store the decoder states together with the corresponding output tokens—the tokens that are actually in the training data, regardless of what the softmax predicts. At inference time, they retrieve the nearest neighbors from the storage (in practice, they do 64 neighbors), normalize their distances using a softmax, and interpolate the new distribution with the standard prediction of the MT model. The combination of the nearest neighbor search and the standard output distribution is well shown on Figure 1 of the paper:
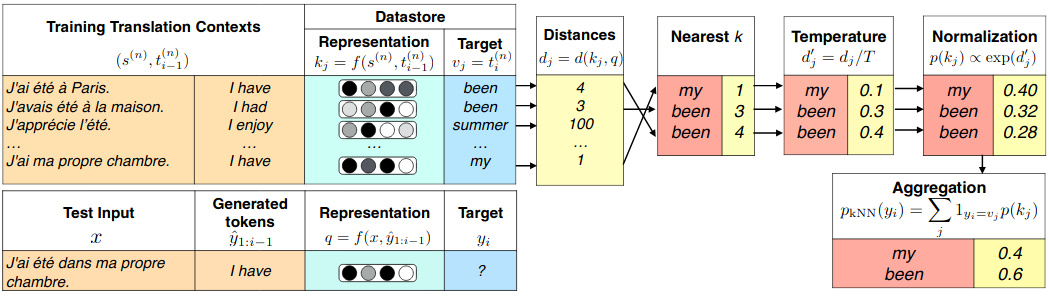
The method reached a consistent improvement over setups they tested in the paper. One noteworthy result is 1.5 BLEU point improvement on the WMT19 English-to-German data. The result shows that with the standard training setup, the model has all the information and representation-learning capability to reach such translation quality. Still, it is just not possible to push it through the bottleneck of the last model layer.
Unfortunately, querying the storage slows down the inference significantly. The paper does not report any exact times, and only says it is two orders of magnitude slower, so at least a hundred times, but perhaps even more. This is a real pity, and I hope that people will come with some potential speedups. Straightforward ideas probably are some knowledge distillation or reducing the storage size by clustering and assigning token distribution to the clusters.
It seems to be a similar thing as we already saw with Word2Vec in 2013. Word2Vec is trained using a modified language-modeling objective that is additionally modified for better speed. In the end, it is a relatively poor language model, but still, the learned representations are very expressive—and very well-suited for nearest neighbor search too. The representation-learning capability of (at least some) deep learning models seems to be better than the capability to learn the task it is trained for. Hopefully, someone smarter than me thinks that too and will come with some better methods for modeling model outputs.
Share the post
@misc{libovicky2020blog1010,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 54: Nearest Neighbor MT",
year = "2020",
month = oct,
url = "https://jlibovicky.github.io/2020/10/10/MT-Weekly-Nearest-Neighbors",
note = "Online, Accessed: 05.06. 2026"
}