 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 44: Tangled up in BLEU (and not blue)
For quite a while, machine translation is approached as a behaviorist simulation. Don’t you know what a good translation is? It does not matter, you can just simulate what humans do. Don’t you know how to measure if something is a good translation? It does not matter, you can simulate what humans do again.
Things seem easy. We learn how to translate from tons of training data that were translated by humans. When we want to measure how well the model simulates human translation, we just measure the similarity between the model outputs and human translation. The only thing we need is a good sentence similarity measure and in the realm of behaviorist simulation, a good similarity measure must correlate well with human judgments about the translations. (So far, it ends here, but maybe in the future, we will move the next level to develop an evaluation metric for evaluation metric and compare it with human judgment, ha ha.)
The BLEU score from 2002 became de facto standard in machine translation evaluation. It has been criticized from the very beginning, but it is very easy to compute and was believed to reasonably correlate with human judgment. Several later metrics correlate much better with human judgment, but all previous work in machine translation used BLEU, so it makes sense to report it too when you want to compare your work with the previous ones. A recent paper from the University of Melbourne, titled Tangled up in BLEU: Reevaluating the Evaluation of Automatic Machine Translation Evaluation Metrics shows that continuing using BLEU is a much worse idea than it might seem.
The paper critically revisits how machine translation metrics are evaluated and disproves the current mainstream opinion that BLEU is not that bad. Indeed, it is simple and transparent, but it correlates with human judgment much less than the previous studies claim.
Machine translation metrics are annually evaluated within the WMT evaluation campaign. Primarily, WMT is a competition in machine translation. Competing teams should deliver translations of a test set and the translations get evaluated by human annotators. As a side effect, the data collected in the evaluation campaign can serve for comparing how well evaluation metrics correlate with human judgment. Because the goal of the evaluation is to rank the systems, it might seem that we should measure Spearman’s correlation. However, the differences between the systems are usually rather small, so even small changes in the scores can lead to large differences in the ranking. Therefore, Person’s correlation is used instead. Pearson’s correlation is known to be sensitive to outliers and to be rather unreliable in the for small populations. This is exactly what we have in the WMT evaluation campaign: there are around 10-15 systems per language pair which is quite a small population, with some systems being remarkably bad.
The spectacular end of the story of the paper is: when we remove the obvious outliers, Pearson’s correlation dramatically changes. In the case of the BLEU score drops a lot. After all, assigning a low score to a bad system is easier than correctly assess a pack of almost the same systems.
The figure below (Figure 3a on page 6 of the paper) shows how the correlation of BLEU and YiSi-1 with human judgment changes after removing outliers (the blue line is with outlier, the orange one is without them):
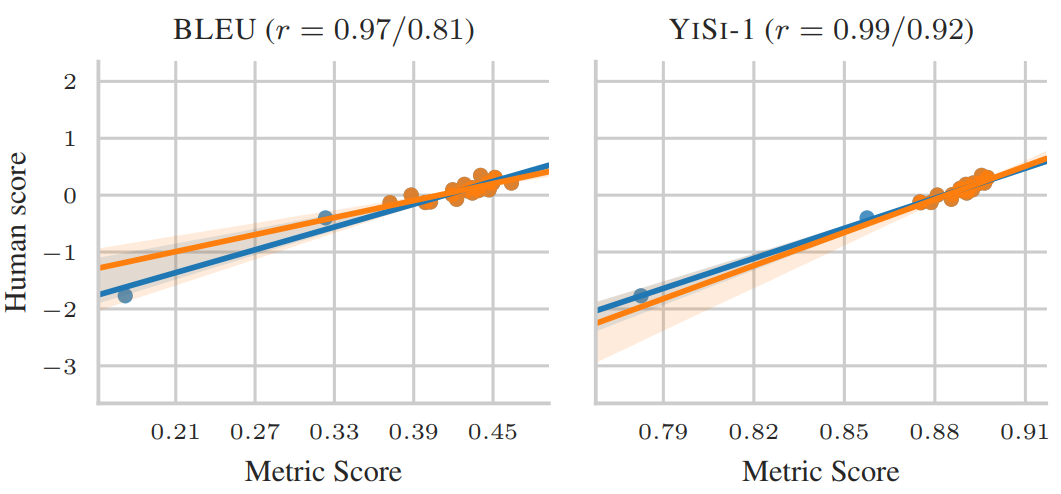
The conclusions of the paper are clear: do not trust differences in BLUE unless they are really big. The paper recommends using other metrics, in particular chrF, ESIM, and YiSi-1, that ended up much better in this critical re-evaluation. I would rather caution against the latter two. Although chrF does not correlate with human judgment as well as the other two, it is similarly transparent as BLEU. It treats the sentences as a bag of character 3-grams and computes a weighted F-measure.
The other two metrics rely on BERT that is a black-box model. What if BERT just does not like some formulation and using BERT-based metrics will cut off promising a research direction? And what do we do when we have much better contextual embeddings than BERT? Do we recompute all results?
Share the post
@misc{libovicky2020blog0619,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 44: Tangled up in BLEU (and not blue)",
year = "2020",
month = jun,
url = "https://jlibovicky.github.io/2020/06/19/MT-Weekly-Tangled-up-in-BLEU",
note = "Online, Accessed: 05.06. 2026"
}