 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 35: Word Translation of Transformer Layers
I always rationalized the encoder-decoder architecture as a conditional language model. The decoder is the language model, the component that “knows” the target language (whatever it means) and uses the encoder as an external memory, so it does not forget what it was talking about. A recent paper from Saarland University in collaboration with two Chinese institutions shows it might be actually the other way round. The encoder does a large part of the translation, the decoder is only responsible for the correct ordering of words. The title of the paper is Analyzing Word Translation of Transformer Layers and its preprint was uploaded this week to arXiv.
The paper comes up with a new cool method on how to show that. They try to estimate how much each layer of the encoder and the decoder knows about the words in the target sentence. (At least to me the method sounds inventive because I was thinking about a similar thing a year ago and did not figure out how to do it.) For a trained model and a sentence, they construct a matrix that tells how much a particular state is attended when the decoder generates individual target words. It is like building a permutation matrix. Applying the permutation corresponds to matrix multiplication.
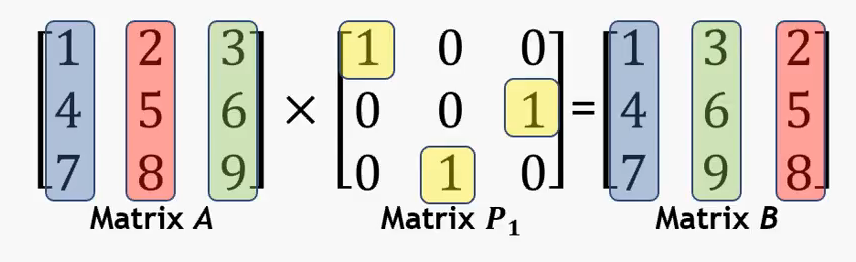
(The figure is taken from a YouTube video tutorial by Mark Judd.)
But unlike the standard permutation matrix, this permutation is soft—each column is a distribution, so you put a bit of each state to each target word position.
This only tells how to transform the last layer of the encoder. But the same principle can be used also between the self-attentive encoder layers, so they can figure out, how each of the layers can be permuted to get the ordering of the target sentence. When they have this, they train a linear layer to classify what word should be at the position and measure how much from the translation they can reconstruct.
From their experiments, it seems that a large part of the translation is happening already in the encoder. Based on the BLEU-1 score (only considers single words), we can estimate that the encoder is already does 77% of translation on the word level. Relatively low standard BLEU score (considers up to word n-grams up to length 4) of the encoder translation, around 40% of the full model, indicates that the decoder is responsible for putting the translation in the correct order. It kind of resembles the conceptualization from statistical machine translation that a separated translation model and a language model.
Another interesting observation is that in the standard 6-layer decoder, the first 4 layers seem to know pretty much nothing about how the translation will look like. The results suggest that we can trade the decoder depth for the encoder depth and gain some speed-up. Unlike decoder, encoder layers can be fully parallelized because the encoder knows the entire source sentence in advance and does not have to wait for the left-to-right decoded target. This conjecture is confirmed by experiments that show a 9-layer encoder and a 3-layer decoder is a reasonable choice.
Their findings are quite surprising to me. The encoder is more important than the decoder. Would you ever say that?
Share the post
@misc{libovicky2020blog0327,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 35: Word Translation of Transformer Layers",
year = "2020",
month = mar,
url = "https://jlibovicky.github.io/2020/03/27/MT-Weekly-Translation-on-Tranformer-Layers",
note = "Online, Accessed: 05.06. 2026"
}