 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 29: Encode, Tag, Realize - sequence transformation by learned edit operations
This week I will have a look at a paper from last year’s EMNLP that introduces a relatively simple architecture for sequence generation when the target sequence is very similar to the source sequence. The title of the paper is “Encode, Tag, Realize: High-Precisions Text Editing” and was written by authors from Google Research (and was recently also presented at Google AI Blog).
There are several natural language processing tasks where the goal is to generate some text which is very similar to the input. In the paper, the tasks are text simplification, document summarization (two tasks which are obviously interesting for Google’s assistant) and grammatical error correction. For these tasks, we usually use the same models as for machine translation: encoder-decoder models where the encoder processes the source sentence and the decoder takes its output and uses it to generate the target sentence.
The disadvantage of these models is that they require large training data because the decoder basically needs to learn the entire grammar of the language to generate fluent sentences. Also, these architectures (especially if they are undertrained) suffer from the hallucination problem when the decoder prefers fluency of the output at the expense of adequacy.
The approach in this paper is different: they represent the process of sequence
generation as applying edit operations on the source sentence. The basic edit
operations are KEEP and DELETE and they can be accompanied with n-grams
from vocabulary telling what words should be inserted. This means an extreme
reduction of the vocabulary, the vocabulary does not have to contain words like
arachnophobia, it can just say KEEP and take care of the rest of the
summary which would be typically playing around with pronouns and function
words.
How the model works is illustrated in Figure 1 of the paper:
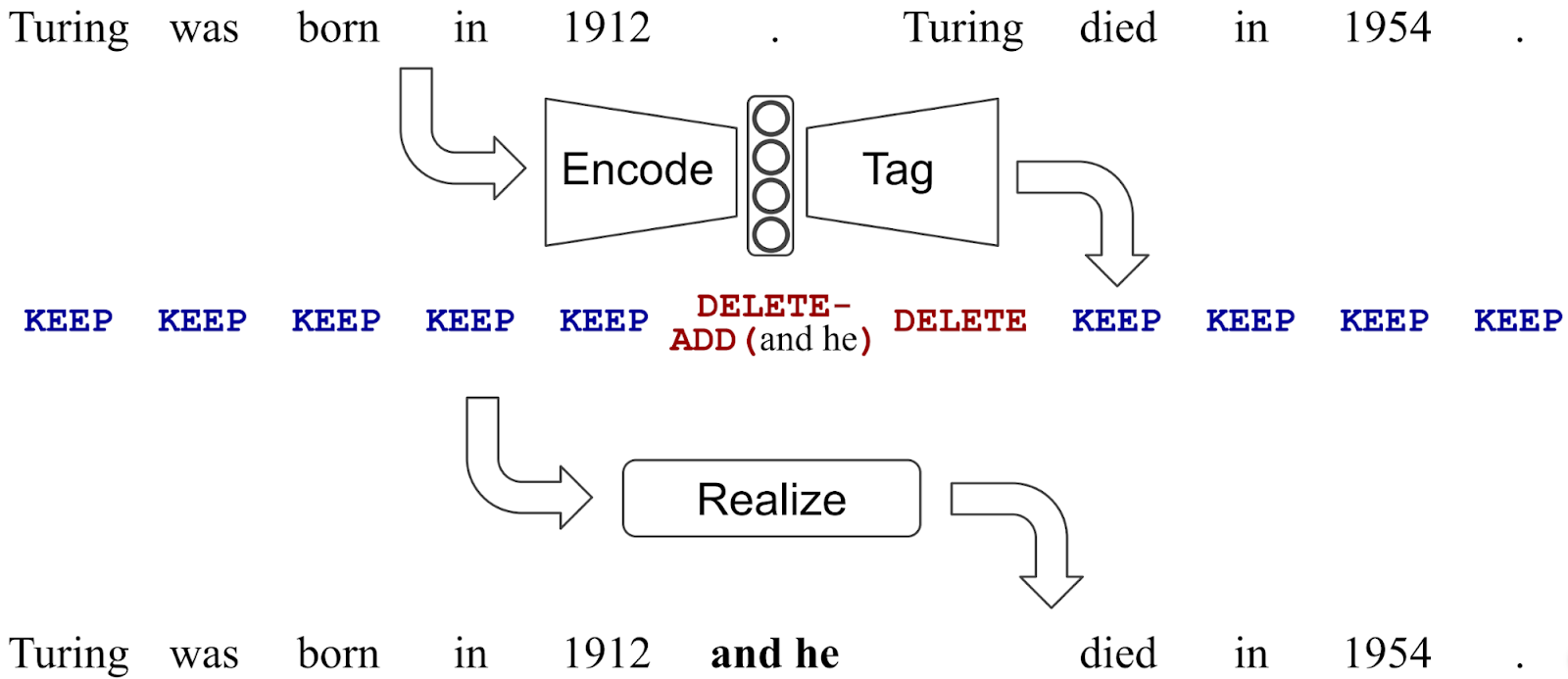
An immediate objection when you see the diagram is that it can only work under specific circumstances. With a limited vocabulary, not all sentence pairs can be encoded like this. In an extreme case, we would need to delete the whole source sentence and rewrite it, but with this rigid scheme, we would need to have the entire target sentence in the insertion vocabulary which is indeed nonsense.
Obviously, the success of this method strongly depends on having the right vocabulary. Getting an optimal solution is an NP-hard problem, so the paper proposes a simple heuristic. For each sentence pair, they find the longest common subsequence and put everything that is outside the common subsequence into a candidate vocabulary. Then, they take just the most frequent one n-grams as the model vocabulary. Training examples that cannot be encoded with the vocabulary are just discarded and it is surprisingly only a few of them.
If you are interested in the algorithm that encodes the sentences pairs, into the tags, have a look at the slideshow:
Now, when we have the sentences encoded, we can start training the tagger. As an encoder, they use the large version of BERT. The decoder is either one additional self-attentive layer or a single-layer autoregressive decoder.
The model reaches state-of-the-art results almost all tasks they tried (sentence fusion, sentence splitting, abstractive summarization) except grammatical error correction where the best approach includes synthetic data generation. The results in terms of quality are not dramatically different from training a large sequence-to-sequence model. The biggest advantage is that the model works remarkably well even with relatively small training data. This is well illustrated in Figure 5 of the paper:
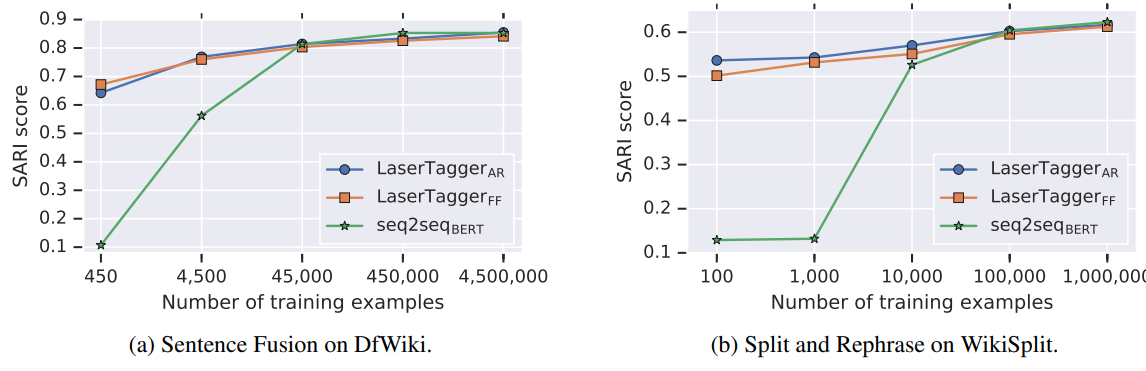
Also, the model is much faster at inference time because it got rid of the big fat autoregressive decoder that has many layers and computes an output distribution over a large vocabulary.
I was quite surprised by the results saying that the non-autoregressive tagger is much worse than the autoregressive one. The autoregressive decoder conditions the output on the previously generated outputs. This is indeed a great advantage when you generate a real sentence. In this case, there is no really informative grammar in the target symbols. The decoder would need to decipher what the meaning of the tag is to be able to condition the following tag on the previous one. This seems to me like a difficult task for a single layer decoder.
The reason why I think the paper is cool is that it presents an approach that is very affordable because it works with a small amount of training data and modest resources at inference time. I would very much like to see something like this working for machine translation of similar languages, however, this would require a better tagging algorithm than relying on the longest common subsequence for training data preparation.
The biggest drawback of the method is that it probably cannot be used off the shelf for inflective languages. Many of the edits that in English do not change much would result in changes in declination and conjugation of sometimes distant words. One would probably need to go for morphological analysis and generation which does fit well in the BERT’s subword universe.
@inproceedings{malmi-etal-2019-encode,
title = "Encode, Tag, Realize: High-Precision Text Editing",
author = "Malmi, Eric and Krause, Sebastian and Rothe, Sascha and Mirylenka, Daniil and Severyn, Aliaksei",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-1510",
doi = "10.18653/v1/D19-1510",
pages = "5054--5065",
}
Share the post
@misc{libovicky2020blog0212,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 29: Encode, Tag, Realize - sequence transformation by learned edit operations",
year = "2020",
month = feb,
url = "https://jlibovicky.github.io/2020/02/12/MT-Weekly-Encoder-Tag-Realize",
note = "Online, Accessed: 05.06. 2026"
}