 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 22: Understanding Knowledge Distillation in Non-Autoregressive Machine Translation
Last week, I discussed a paper claiming that forward-translation might be a better data augmentation technique than back-translation. This week, I will follow with a paper that touches a similar topic, but in a slightly different context. The title of the paper is Understanding Knowledge Distillation in Non-Autoregressive Machine Translation and was uploaded to arXiv by the authors from CMU and Facebook a month ago.
Standard (i.e., autoregressive) models generate the translation word-by-word and every word (or sub-word) generated is conditioned by the previously generated ones. In the Transformer architecture, all computations can be heavily parallelized except for the decoding (that needs to wait for previous words) which poses a speed bottleneck. Non-autoregressive models remove this bottleneck at the expense of the translation quality and generate the target sentences in a single parallel step.
We talk about knowledge distillation when a simpler model (student) is trained not using real training data, but using outputs of a stronger model (teacher). Knowledge distillation techniques often use KL-divergence between the teacher and the student models output distributions as a loss function. With non-autoregressive machine translation, it is a kind of degenerate special case. We want the student model to generate the same output symbol as the teacher model, regardless of the probability distribution that was at the output of the teacher model. After all, it would not make much sense here, because autoregressive models are trained to model conditional distributions, whereas in the non-autoregressive model outputs are conditionally independent. In other words, here, knowledge distillation is the same as data augmentation by forward-translation by Nikolay Bogoychev and Rico Sennrich that I discussed last week.
The reason why knowledge distillation is discussed in the context of non-autoregressive models is that knowledge distillation brings large improvements in translation quality. The paper I am going look into tries to find out why it is the case.
Once again how does the knowledge distillation work with non-autoregressive models:
-
An autoregressive model is trained and used to translate the source side of the training data.
-
The training data with the synthetic target side are then used to train the non-autoregressive model.
The hypothesis the paper promotes is that the knowledge distillation limits the diversity of the translations and which helps the non-autoregressive models to generate more coherent translations. They call diversity multimodality, which seems a little misleading to me, as if there were modalities other than text (like speech, vision, smell, …). What they mean is that the distribution over target sentences has multiple modes (i.e., local maxima in the density function) for multiple plausible translations. They hypothesize that autoregressive models tend to model the distribution of output sentences unimodally, in other words, they consistently choose one mode. The biggest empirical weakness of the non-autoregressive models is that they often mess up word order and do not cover the entire source sentence because they chose two mutually inconsistent way of translation. For instance, our non-autoregressive models with CTC had problem with translating past sentences into German because it mixed both German ways of expressing the past tense (one modifies the verb itself, the other is a combination of an auxiliary verb and a participle form). If the teacher model is consistent in this, the student model might not be so confused.
In the paper, they test this hypothesis with an interesting toy experiment. They train models that translate from English into German, French, and Spanish at the same time without telling the model what the target language should be—every English sentence has three different targets in the training data. At test time, the model picks the target language basically randomly. The results were that:
-
The autoregressive model indeed chose the language randomly, but it was always very confident about the decisions.
-
The non-autoregressive models were always very unsure about what target language to chose.
They show it on a cool visualization (distribution over 3 values can be shown as 2D simplex):
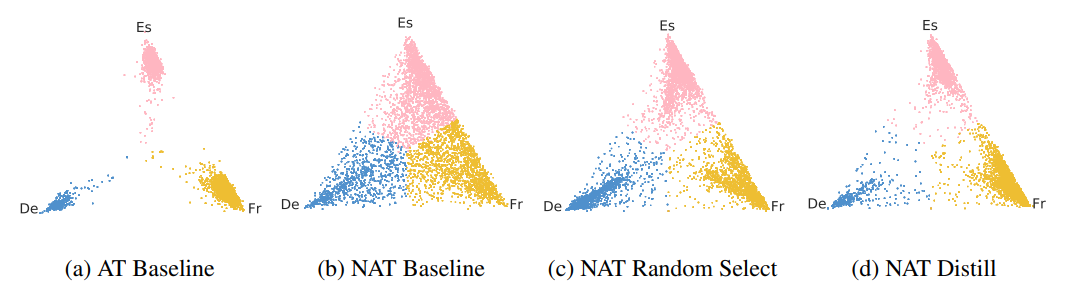
The first experiment suggests that the outputs of autoregressive models tend to be structurally consistent. In another experiment, they show that outputs of the autoregressive models are also more lexically consistent than real data. (At least this is my humble interpretation of the experiments.) They measure the training data entropy given a word alignment model fitted on the data. They use a simple probabilistic model that assumes that every target word was generated from a source word with some probability. It turns out that the synthetic data have much lower entropy under this model which again suggest more coherence and less diversity.
Finally, they do an empirical evaluation that shows that like everything in MT, nor knowledge distillation has a simple recipe on how to train the best system. Different teacher models perform differently with different student models. Nevertheless, the main result is that if we find a correct combination, a non-autoregressive model might as good an autoregressive one.
Getting back to the last week’s paper, the experiments in this paper might also be the answer to why forward-translation as a data augmentation technique works well, given the parent model is good. It might be the bigger consistency (unimodality) of the synthetic data that prevents the model from being too distracted by the variability in the real-world training data. The effect is obviously not that big with autoregressive models because they do not suffer from problems with coherence, but it might part of the reason why it helps.
@article{zhou2019understanding,
title={Understanding Knowledge Distillation in Non-autoregressive Machine Translation},
author={Zhou, Chunting and Neubig, Graham and Gu, Jiatao},
journal={arXiv preprint arXiv:1911.02727},
year={2019}
}
Share the post
@misc{libovicky2019blog1206,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 22: Understanding Knowledge Distillation in Non-Autoregressive Machine Translation",
year = "2019",
month = dec,
url = "https://jlibovicky.github.io/2019/12/06/MT-Weekly-Knowledge-Distilation-with-Nonautoregressive-Models",
note = "Online, Accessed: 05.06. 2026"
}