 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 12: Memory-Augmented Networks
Five years ago when deep learning slowly started to be cool, there was a paper called Neural Turing Machines (which are not really Turing machines, but at least they are neural in a narrow technical sense). The paper left me with a foolishly naive impression that it might be the beginning of the end of computer science as we know it. (And also with an impression that everything I do for my Ph.D. is hopelessly bad compared to such cool papers.)
The paper introduces an architecture that attempts to mimic how the Turing machine operates. Instead of a potentially infinite memory tape, it has a constant-sized memory matrix that is addressed using the attention mechanism (which was not known as the attention mechanism at that time) for read and write operations. It was showcased on a few simple algorithmic tasks and it kind of worked. (It can learn to sort numbers, isn’t that great?) I secretly hoped that soon more powerful architectures would be invented and eventually, we might have models able to pick up what a program should do based on dozens of examples. Programmers could have been the first ones to lose jobs due to AI. (Wouldn’t that be great?)
The architecture of the Neural Turing Machine was not only the main source of inspiration for the attention mechanism, one of the most important ideas in natural language processing of the last couple of years, but it also gave birth to a research direction exploring neural architectures called Memory-Augmented Networks. The main feature of these neural networks is that they explicitly read-and-write memories which sort of mimics how current computer programs work and also makes the computation of the network a little bit more interpretable. They are usually tested on theoretically motivated algorithmic tasks, which always makes me suspect that they might not work on more real-world tasks.
The reason why I am talking about this is that a paper called Memory-Augmented Neural Networks for Machine Translation from Trinity College Dublin recently showed how these architectures can work when applied on machine translation. In the standard encoder-decoder architecture, the encoder processes the source sentence and the decoder uses the attention mechanism to collect relevant information from the encoder. From the perspective of the memory networks, the decoder uses the encoder outputs as a memory from which it only can read. In the fully memory-network setup presented in the paper, the encoder has read-write access to the memory and so does the decoder. First, the model must learn to write the relevant pieces of information in the memory and then, during the decoding, read what was written in the memory and eventually delete what is no longer of use. This is illustrated well on a scheme in the paper:
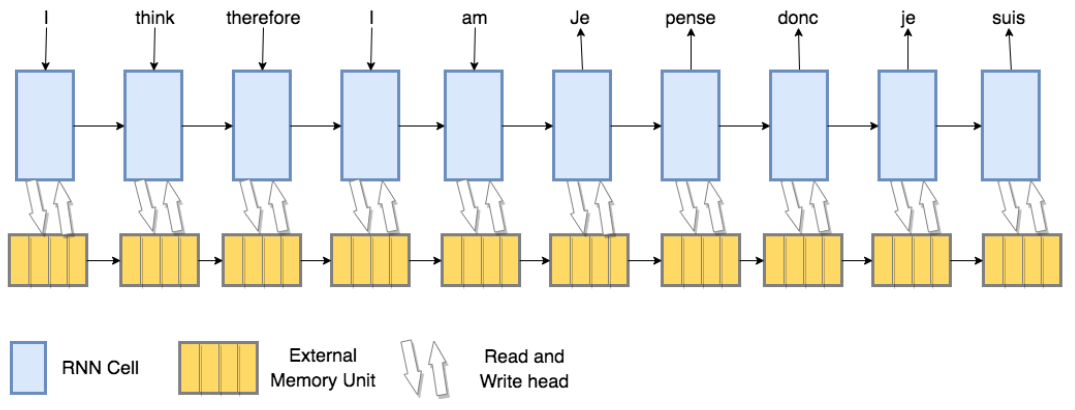
As mention earlier, the paper shows that it is indeed possible to train a model like this. The analysis of the read and write gates shows that they do exactly what was expected. It even outperforms the standard architecture for English-Vietnamese translation and gets a bit worse for English-Romanian translation. This (and the fact that the paper does not show any results on high-resource languages) kind of suggests that the more training data you have, the more the memory networks lag behind the more standard approaches. Anyway, it is still cool to see that such a general architecture actually can learn to translate.
A footnote: Does anyone remember the Universal Transformer (the last year’s summer hit)? It applied the same Transformer layer over and over until some criteria were reached. This was also a kind of memory network—the self-attention reads the information from the memory and decides how much it should get overwritten. Maybe we should think more about the notion of memory in machine translation.
BibTeX Reference
@inproceedings{collier2019memory,
title = "Memory-Augmented Neural Networks for Machine Translation",
author = "Collier, Mark and
Beel, Joeran",
booktitle = "Proceedings of Machine Translation Summit XVII Volume 1: Research Track",
month = "19{--}23 " # aug,
year = "2019",
address = "Dublin, Ireland",
publisher = "European Association for Machine Translation",
url = "https://www.aclweb.org/anthology/W19-6617",
pages = "172--181",
}
Share the post
@misc{libovicky2019blog0926,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 12: Memory-Augmented Networks",
year = "2019",
month = sep,
url = "https://jlibovicky.github.io/2019/09/26/MT-Weekly-Memory-Networks",
note = "Online, Accessed: 05.06. 2026"
}