 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 10: Massively Multilingual Neural Machine Translation
The holiday period is over and I almost settled in my new place of operation which is the Ludwig-Maximilian University of Munich, and now there is nothing that can prevent me from continuing with weekly reports on what is new in the world of machine translation and natural language processing.
This week, I will discuss two related papers that recently popped up on arXiv. The papers were written by quite an overlapping group of authors from Google and both of them deal with massively multilingual translation models. The first one is accepted to EMNLP 2019 and is called Investigation Multilingual NMT Representations at Scale, the second one is called Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation.
Both of the papers probe sentence representations that emerge in two newly developed machine translation models. One of them is capable of translating from English into 102 different languages, the other one works the other way round. The drop of the translation quality compared to language-specific models (which means 204 translation models, each of them several gigabytes large) is only 0.25 BLEU on average. It mostly drops for high-resource languages whereas for low-resourced languages it usually increases. This itself is an amazing achievement.
The main finding of the first paper is that the vector representations from the encoder tend to cluster according to language families as can be seen in the figure below. They took vectors (of 512 dimensions!) from the encoder part of the network, compute the average over the sentences and drew a 2D projection that more or less preserves the distances in the original high-dimensional space.
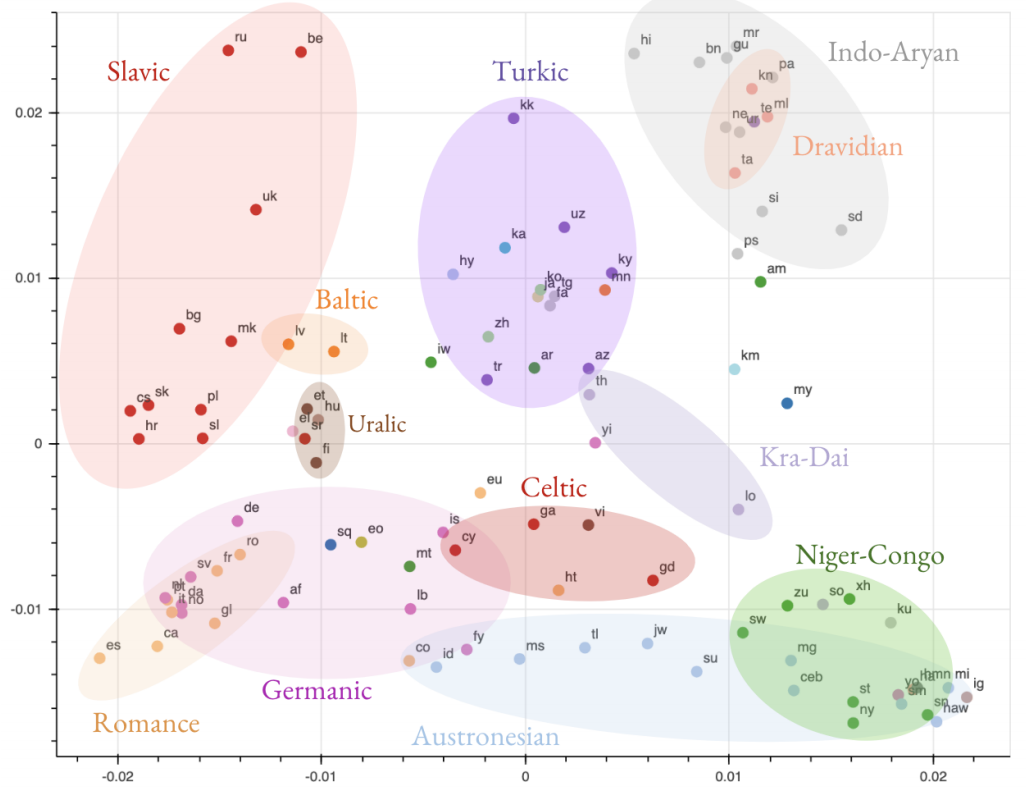
In the first layers of the models, the representations tend to cluster based on what scripts the languages use. In the later layers, it seems the network abstracts away from this and captures more the similarity based on language families phylogenetic distances. Isn’t it fascinating? These structures arise in the network without explicitly teaching them to do so. It just, by the way, emerges while learning to translate from 102 languages into English.
The second paper explores options to use the sentence representations from the multilingual models in other natural language tasks. The results are not so exciting as in the first paper. Many of the tasks are rather artificial: part-of-speech-tagging in many languages at once, multilingual exercise from predicate logic called natural language inference, etc. The second reason is that the representations seem to be similarly good as Multilingual BERT. Unlike the machine translation model, BERT is trained to predict masked-out words in a sentence, so the model does not have any supervision other than plain text. Multilingual NMT, on the other hand, can use the English translation as a means of tying the representations together. I would thus expect that the common training signal can make the representations more cross-lingual. It does not happen and the paper does not discuss why.
BibTeX Reference
@article{siddhant2019evaluating,
title = {Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation},
author = {Siddhant, Aditya and Johnson, Melvin and Tsai, Henry and Arivazhagan, Naveen and Riesa, Jason and Bapna, Ankur and Firat, Orhan and Raman, Karthik},
url = {http://arxiv.org/abs/1909.00437},
month = sep,
year = {2019},
note = {arXiv: 1909.00437},
journal = {arXiv:1909.00437 [cs]},
}
@article{kudugunta2019investigating2019,
title = {Investigating Multilingual {NMT} Representations at Scale},
author = {Kudugunta, Sneha Reddy and Bapna, Ankur and Caswell, Isaac and Arivazhagan, Naveen and Firat, Orhan},
url = {http://arxiv.org/abs/1909.02197},
month = sep,
year = {2019},
note = {arXiv: 1909.02197},
annote = {Comment: Paper at EMNLP 2019},
journal = {arXiv:1909.02197 [cs]},
}
Share the post
@misc{libovicky2019blog0911,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 10: Massively Multilingual Neural Machine Translation",
year = "2019",
month = sep,
url = "https://jlibovicky.github.io/2019/09/11/MT-Weekly-Massively-Multilingual-NMT",
note = "Online, Accessed: 05.06. 2026"
}