 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 5: Revisiting Low-Resource Neural Machine Translation
Let’s continue with pre-prints of papers which are going to appear at ACL this year and have a look at another paper that comes from the University of Edinburgh, titled Revisiting Low-Resource Neural Machine Translation: A Case Study.
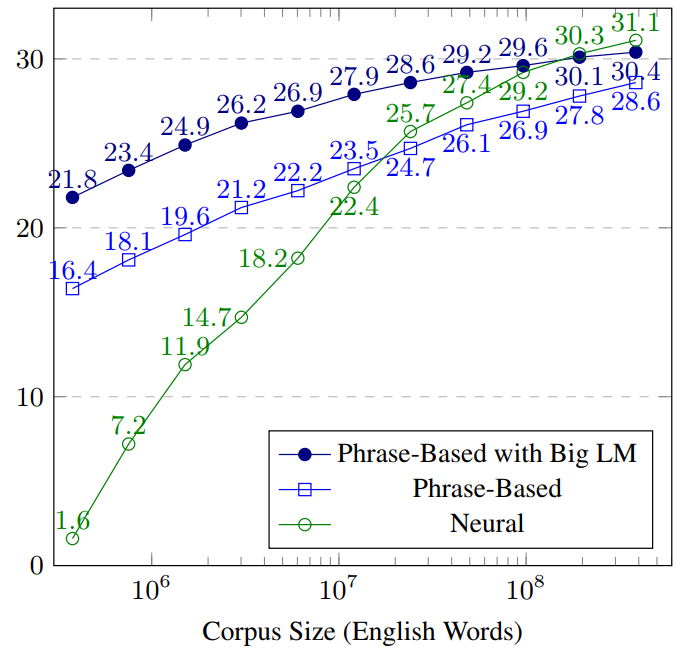
This paper is a reaction to an influential 2-years-old paper called Six Challenges for Neural Machine Translation, which despite being a workshop paper, already collected 168 citations according to Google Scholar. Among other claims, it says that neural machine translation is extremely data-hungry and outperforms the previously used statistical MT only when trained on parallel data bigger than 107 words, and 108 words if the statistical model makes use of monolingual data.
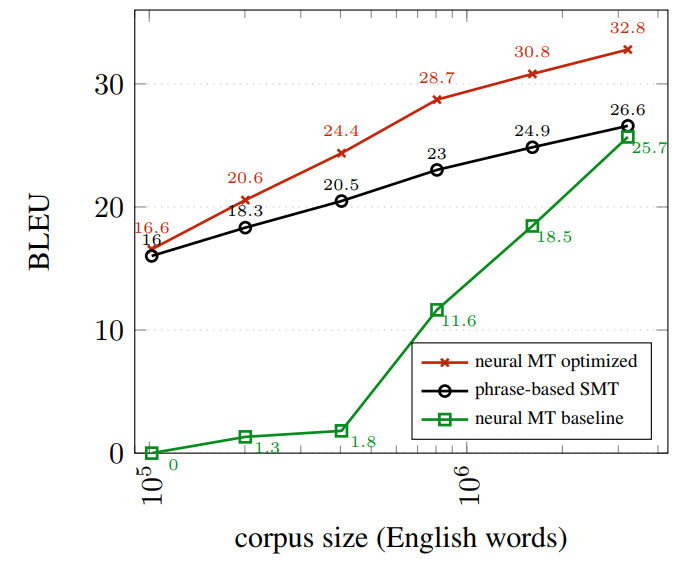
Now after 2 years, researchers from Edinburgh revisited this problem and came to an entirely different conclusion. Neural machine translation outperforms the statistical models as soon as they are trained on a parallel corpus of at least 105 words. A part of the reasons the results are dramatically different after just 2 years are many innovations that were not known or were not common back at that time: layer normalization, tying embeddings, label smoothing, clever dropout strategies. But most importantly, the experiments suffered from a kind of methodological bug – model hyperparameters were tuned on the large data and then applied on the small data with which they (not surprisingly) did not perform well.
The left part of the picture below shows the original plot from two years ago – the neural models seem to be desperately data-inefficient. The plot on the right side shows the remade experiments. The green line corresponds to the same setup (and basically the same results) as used in the original paper, the red line is a neural system trained with all the tricks and hyperparameters tuned for small training data.
And what tricks to make the system train so well? They are surprisingly easy:
-
Reduce vocabulary (here from 14k to 2k subword units), so pretty much everything gets split into subword units;
-
Reduce the batch size (and thus get more, but noisier updates during training);
-
Add word dropout (and prepare the model, that it will inputs that will seem very broken given what was in the training data);
-
Reduce the number of layers; and
-
Tune learning rate, and label smoothing rate (the data is small after all, you can afford it).
It is as simple as that. I guess from now, there is officially no excuse not to use neural MT and keep using the statistical models. The neural revolution in machine translation is now complete (ha, ha).
BibTeX Reference
@inproceedings{sennrich2019revisiting,
title = "Revisiting Low-Resource Neural Machine Translation: A Case Study",
author = "Sennrich, Rico and
Zhang, Biao",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1021",
doi = "10.18653/v1/P19-1021",
pages = "211--221",
}
Share the post
@misc{libovicky2019blog0604,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 5: Revisiting Low-Resource Neural Machine Translation",
year = "2019",
month = jun,
url = "https://jlibovicky.github.io/2019/06/04/MT-Weekly-Revisiting-Low-Resource-NMT",
note = "Online, Accessed: 05.06. 2026"
}