 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 4: Analyzing Multi-Head Self-Attention
With the ACL camera-ready deadline slowly approaching, future ACL papers start to pop up on arXiv. One of those which went public just a few days ago is a paper called Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned written by quite a diverse group of researchers from University of Amsterdam, University of Edinburgh, Moscow Institute of Physics and Technology and Russian company Yandex.
The paper analyzes the encoder of the Transformer models for machine translation and tries to get to the bottom of what the self-attention heads in the encoder do. The self-attention is known to capture some linguistic phenomena, but most of the attention heads learn to do “mysterious” operations that no one can really interpret. It is indeed tempting to think that this is one of the things that make the Transformer such a powerful model. However, this paper shows that exactly these heads are the most superfluous ones and if you (cleverly) remove them from an already trained model, the translation is quality is not harmed at all.
First, let me remind you how the self-attention heads in the Transformer model look like. (Click to unroll if you are interested in a clumsy summary or just skip it.)
The inputs of the encoder are word embedding vectors. A word vector in the next sublayer is a combination of the vectors on the previous layers, more precisely a linear combination of outputs of so-called heads. Each head computes a probability distribution over all vectors in the layer and uses it to compute a weighted sum of learned projections of the vectors. The distribution can be interpreted as information to which words a word attends (is attached?) on a particular layer. This interpretation is what this paper discussed here is most concerned with. When visualized, the self-attention heads can look like this (taken from Google AI Blog announcing the Transformer paper).
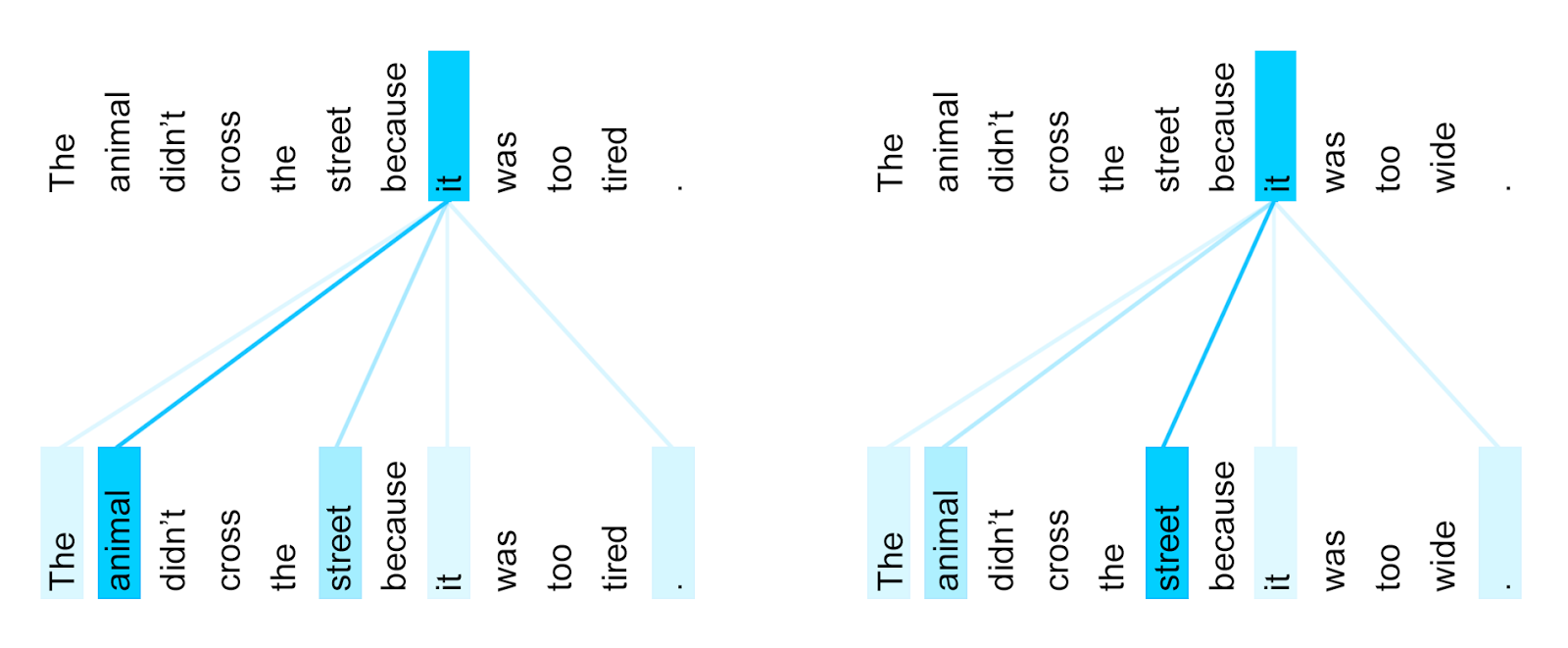
The self-attentive layers are interleaved with simple multilayer-perceptron-like non-linear layers. There are also residual connections between all sublayers which kind of make sure that the information about the words stays locally and does travel arbitrarily among the states. (It is an important, yet unspoken assumption of the discussed paper.) The encoder usually has 8 attention heads in each of its 6 layers, it means 48 heads in total.
If you need even more details about the Transformer model, you can, of course, read the original paper, but you can also have a look at nice illustrations by Jay Alammar.
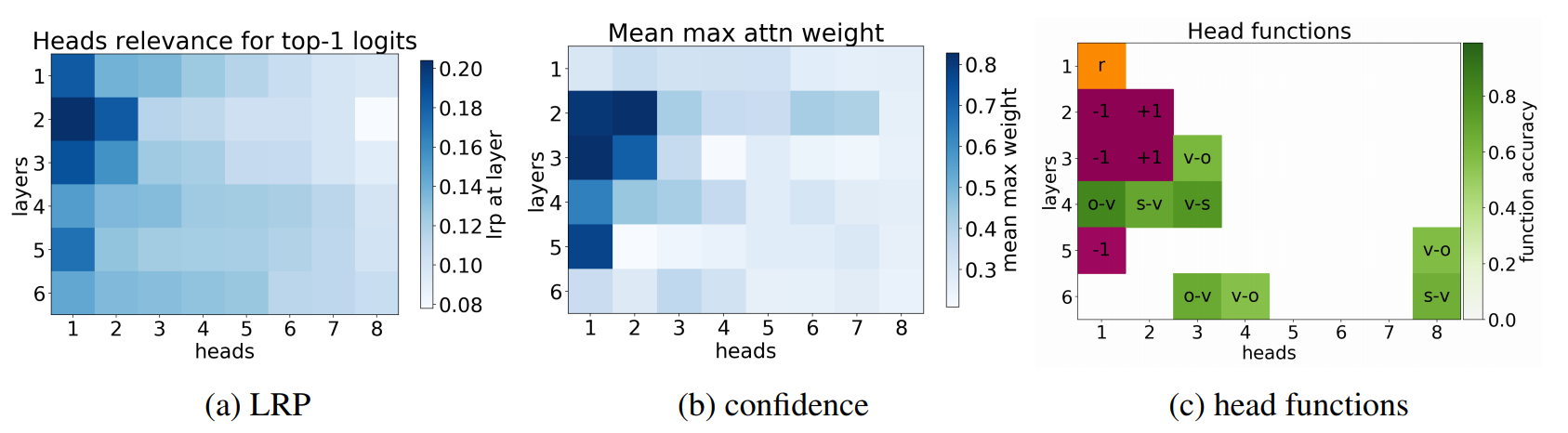
The paper classifies the attention heads into several categories. In the first category, there are position heads, systematically attending to surrounding words at a fixed relative position (the Transformer is by design not aware of word order and needs to learn it). The second category consists of so-called syntactic heads. The authors came up with a clever technique (which might be enough for a separate paper) and detected heads that reach the maximum values when attending from one syntactic category to another one. There are heads identifying object-verb relation, heads attaching verbs with adverbial modifiers, etc. In the third and last category, there are heads attending to statistically rare words. It is hard to say why they are there, perhaps because the rare words tend to say a lot about the topic of the sentence.
After that, they used Layer-wise Relevance Propagation, a technique that estimates the importance of particular neurons for the network output (a really cool thing, I had no idea it existed until now) and also measured how sharp the attention distributions are. And, amazingly, the most important heads according to relevance propagation are those with the sharpest distributions and exactly those from the three categories as is shown on a picture in the paper (the picture is taken from the paper, page 3, figure 1).
This might have been enough for a decent paper, but the story does not end yet. The paper introduces a clever technique for learnable switching off the attention heads. There is a gate added to every attention head (something similar to the Gumbel-softmax) which makes a hard 0/1 decision whether the head is used or not. However, the decision is still differentiable and the gradient can get through during training. It is used for a multi-task model fine-tuning which with two objectives: first, switch off as many heads as possible (maximize the gate probabilities), and, second, minimize cross-entropy of reference sentences (i.e., the standard way of training MT). The more weight is given to the first objective, the more heads get switched off. The experiments again show that the heads from the already mentioned categories tend to survive and the “mysterious” heads are the first ones that get removed, and importantly, it barely influences the translation quality. This is shown on a diagram with the number of remaining heads on the horizontal axis and head categories on the vertical axis (the picture is taken from the paper, page 7, figure 8).
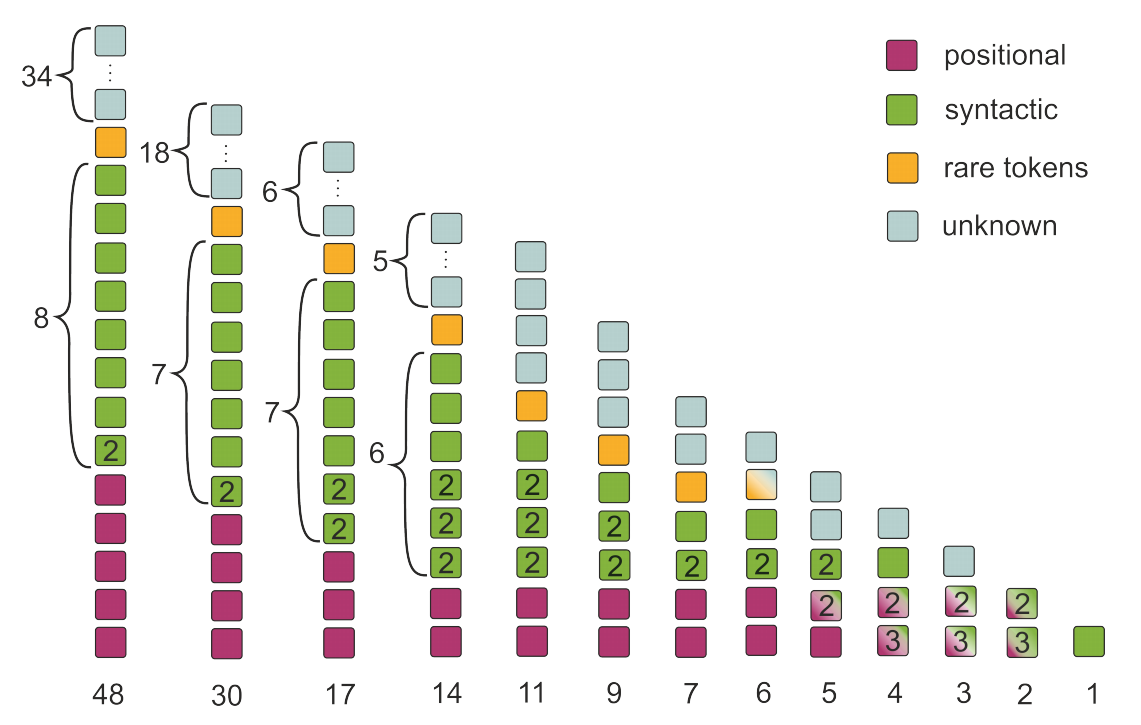
At first glance, the method seems a bit over-engineered, but just removing one of the heads without fine-tuning would certainly break the model immediately. Even if the “mysterious” head only generated noise, the rest of the network would be tuned to the particular type of noise. In fact, this is truly an elegant way of learning to remove something from a neural network without doing much harm.
BibTeX Reference
@inproceedings{voita2019analyzing,
title = "Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned",
author = "Voita, Elena and
Talbot, David and
Moiseev, Fedor and
Sennrich, Rico and
Titov, Ivan",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1580",
doi = "10.18653/v1/P19-1580",
pages = "5797--5808",
}
Share the post
@misc{libovicky2019blog0527,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 4: Analyzing Multi-Head Self-Attention",
year = "2019",
month = may,
url = "https://jlibovicky.github.io/2019/05/27/MT-Weekly-Analyzing-Self-Attention",
note = "Online, Accessed: 05.06. 2026"
}