 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 2: BERTScore
Last week, there was a paper on arXiv that introduces a method for MT evaluation using BERT sentence representation. The metric seems to be the new state of the art in MT evaluation. Its name is BERTScore and was done at Cornell University.
MT evaluation is itself a surprisingly difficult task. The reason is that we are not (and probably never will be) able to explicitly algorithmically check if two sentences carry the same meaning in all relevant aspects. We know (or at least assume) that people can do this assessment even though they don’t know how they do it. We thus treat the whole machine translation as a kind of behaviorist simulation and ground the metrics that we use for MT evaluation in human judgment by measuring the correlation of the metrics with human judgment.
BERT is a neural-network-based sentence representation published by Google in October 2018 including the pre-trained models that are freely available since November. Since then, BERT became one of the most discussed topics in natural language processing.
The BERT model itself is based on the Transformer architecture, originally invented for machine translation. The model is trained to guess input words that were randomly masked out and to decide whether two sentences follow each other. This relatively simple supervision causes that the model develops a very informative sentence representation. Models based on BERT set the new state of the art in many NLP tasks including sentiment analysis, paraphrase detection, finding an answer for a question in a coherent text, syntactic analysis, etc.
And surprise… MT evaluation is another task where BERT rules. According to the results in the paper, BERTScore is the best MT evaluation metric that currently exists. The scoring algorithm is relatively straightforward and proceeds as follows:
-
Get the BERT representation for the translation hypothesis and the reference sentence.
-
Compute a matrix of cosine similarities of all words from the hypothesis and from the reference sentence.
-
For each word from the hypothesis find the most similar word from the reference and compute the average of the maxima over the hypothesis words. This number tells us how much on average each word was matched with a word in the reference. In the paper, they call this precision (which is kind of terminological cheat because the averaged numbers are neither relative frequencies nor probabilities).
-
Do the same with swapped hypotheses and reference and compute recall (with the same terminological cheat).
-
Compute the F1 score: the harmonic average of precision and recall.
The authors themselves summarize it nicely in a picture (Figure 1, on page 4 of the paper):
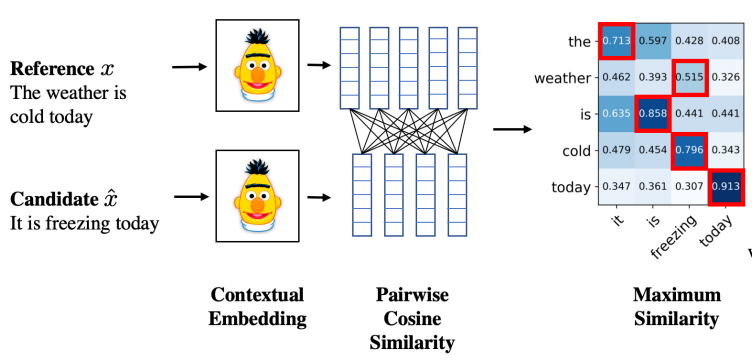
And that’s it, the algorithm is as simple as this. The authors do some additional tricks with IDF score, but it does not seem to influence the score much.
The results are the most interesting in the evaluation of isolated sentence pairs. The correlation with human judgment is around 0.5 with most of currently used metrics and goes over 0.7 with BERTScore.
The margin between BERTScore and the existing metrics is narrower in case of corpus-level metrics. Most of the existing metrics manifest correlation with human judgment between 0.90 and 0.95 which is already pretty high. BERTScore with correlation slightly over 0.95 on average still makes it the best-scoring metric.
Recently, there were many evaluation metrics that achieved a high correlation with humans which are based on supervised learning from previous manual evaluations. This makes the metrics dependent on how the machine translation outputs look like these days and pose a risk that they won’t work well with newer MT systems. BERTScore is independent of how the system outputs currently look like which makes it more robust in the future.
BibTeX reference
@article{zhang2019bertscore,
title = {BERTScore: Evaluating Text Generation with {BERT}},
author = {Tianyi Zhang and
Varsha Kishore and
Felix Wu and
Kilian Q. Weinberger and
Yoav Artzi},
journal = {CoRR},
volume = {abs/1904.09675},
year = {2019},
url = {http://arxiv.org/abs/1904.09675},
archivePrefix = {arXiv},
eprint = {1904.09675},
}
Share the post
@misc{libovicky2019blog0501,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 2: BERTScore",
year = "2019",
month = may,
url = "https://jlibovicky.github.io/2019/05/01/MT-Weekly-BERTScore",
note = "Online, Accessed: 05.06. 2026"
}