 Jindřich's blog
Jindřich's blog


Lessons learned from analyzing values in multilingual encoders and what it means for LLMs
This post is a hindsight on two studies on multilingual sentence embeddings we published a year ago and comments on what I think people analyzing LLMs today should take away from them.
In late 2022, we (which mainly was the work of Kathy Hämmerl from Munich and Björn Diesenroth and Patrick Schramowski from Darmstadt) finished a paper called Speaking Multiple Languages Affects the Moral Bias of Language Models (later published in Findings of ACL 2023) where we tried to compare moral biases in sentence embeddings across languages. Then, I had a short paper Is a Prestigious Job the same as a Prestigious Country? in Findings of EMNLP 2023 using the same methodology to assess what biases multilingual sentence embeddings contain regarding countries and jobs.
Speaking Multiple Languages Affects the Moral Bias of Language Models
The folks from Darmstadt previously developed a cool methodology for getting dominant semantic direction from sentence embeddings. Embeddings are known to carry plenty of information about linguistic structure, such as its morphology and syntax. Mostly, it is a good thing, but it is not ideal when you are interested in high-level semantic or pragmatic aspects like moral bias.
The trick they developed was getting a templated set of sentences with the same linguistic structure that only minimally differs. In this case, these sentences said: “$X$ is morally good.” If $X$ is the only thing that differs, the differences in $X$ should form the dominant direction in the embeddings. It still may not be enough: Some words have unexpected connotations in some contexts, and some sentences sound more natural than others. Therefore, they used a bunch of synonymous templates and averaged their embeddings. Finally, they did PCA on the averaged prompt embeddings obtained this way. After this prompting and linear algebra exercise, they found that the first PCA dimension nicely captures basic moral intuitions.
The follow-up question we decided to work on was: How does it differ across languages (and thus some extent across cultures)? We worked with English, Czech, German, Chinese, and Arabic because they are all high-resource languages and are hopefully represented well by the encoder models. We also hoped to observe some differences between Western and non-Western languages.
We machine-translated the templated sentences and repeated the original experiments. In all languages, the extracted moral dimension looked reasonable and was not far from coarse-grained everyday moral intuitions (which are, to some extent, shared across cultures).
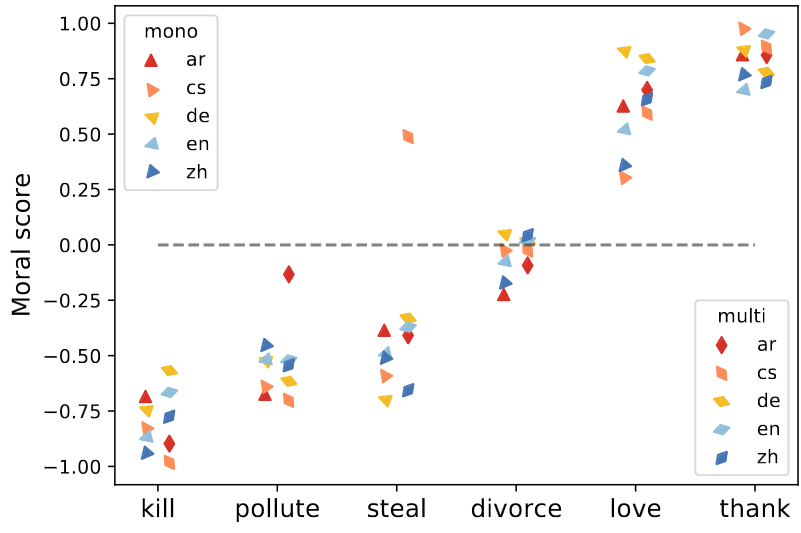
There are differences between languages: Some tend to agree more with each other, and some of them agree less. Surprisingly, languages within a single multilingual model tend to disagree more than multilingual models.
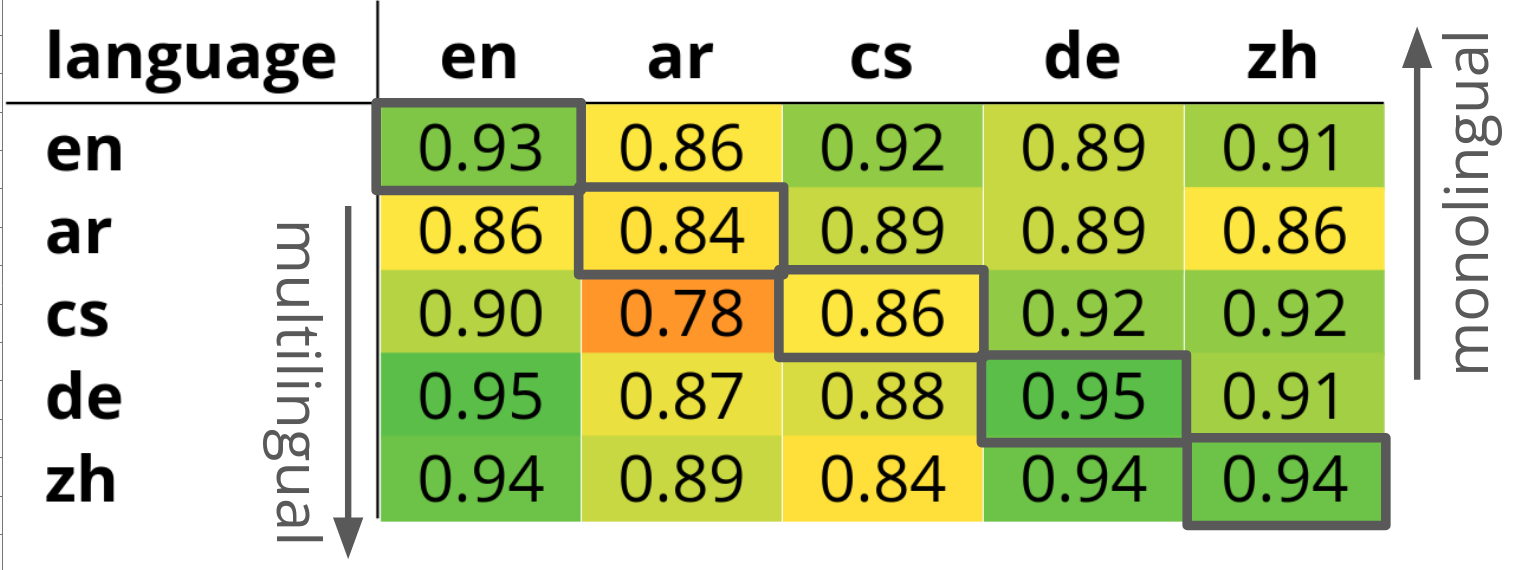
To inspect the differences, we scored parallel sentences and looked at sentences that disagreed the most. Surprisingly, we did not find any cultural differences in the parallel data. Most disagreements could be explained by simply misunderstanding some words across languages. For instance, in German, a Gift means poison, but because it is the same word in English, giving somebody a gift is a good thing; poisoning someone in German also ends up being good.
Even though we knew that the biggest disagreements were actually mistakes, we were still interested in whether there was something systematic in the results. We used statements from moral foundation questionnaires and compared the extracted model dimension with actual answers from countries where the languages are spoken. The model values were in no way close to what the surveys claimed.
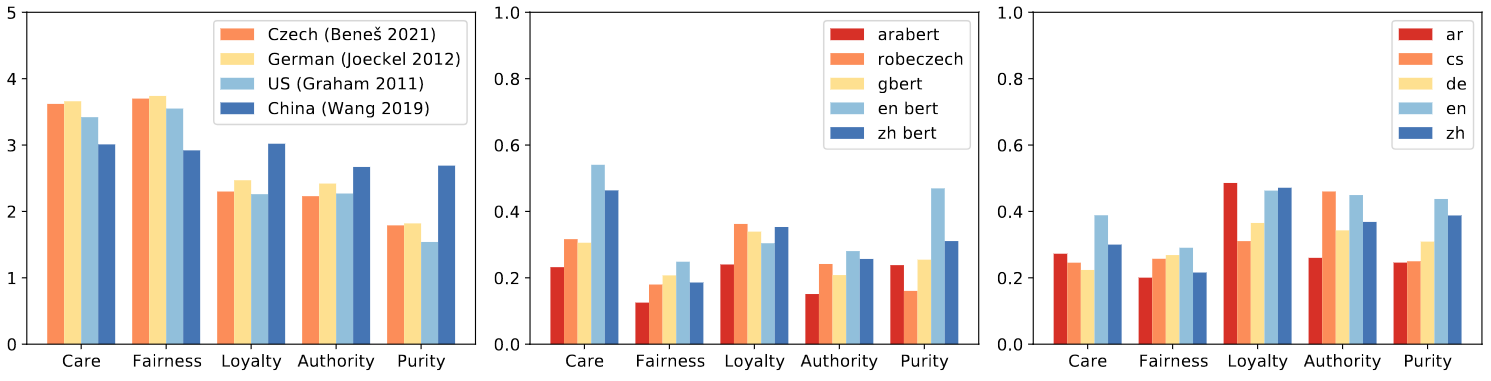
The conclusion is that the models do capture some moral intuitions. However, when we look more carefully, we find that there are nuances across languages and cultures, but they are pretty random.
Is a Prestigious Job the same as a Prestigious Country?
Because I really liked the methodology that so efficiently averages out the influence of the exact prompt formulation, I did a similar study in a different domain. I was interested in a question: if models consider some countries more prestigious than others. Also some jobs more prestigious than others, then the question is if those two types of prestige are represented similarly. Multilingual automatic CV processing would be a total mess if this was the case.
Similar to the previous study, I created templated sentences saying that it is prestigious to come from country $X$ and templates saying that it is prestigious to work in profession $X$. I experimented with 4 multilingual sentence embedding models. I only worked with European languages and European countries because this is the region I am most familiar with, and hopefully I can identify potential biases efficiently.
The results show sort of expected biases: The dimension of country prestige splits Europe into former Eastern and Western blocks, with Western Europe being the more prestigious one. It is also highly correlated to the GDP of the countries. The job prestige dimension corresponds to what people in the US said in a 2012 survey. There were not many differences across languages, and the small differences tended to correlate with language similarity rather than geographical distance or GDP.
Takeaways for analyzing LLMs
One of the main lessons I learned from working on the papers is that prompts matter, and getting rid of the influence of the prompt is not trivial. Unfortunately, I do not know how to easily average out the effect of different prompts in the generative context. Analyzing what is inside the hidden representations of language models is a completely different task than assessing what the outputs a model prefers to generate.
Because of these two papers in my profile, I ended up reviewing papers on similar topics, which do not analyze representation from encoders but prompt LLMs. I am quite surprised that the papers do not even consider the effect of the exact wording of the prompts on the results and do not do anything to get rid of this effect.
Share the post
@misc{libovicky2024blog0723,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Lessons learned from analyzing values in multilingual encoders and what it means for LLMs",
year = "2024",
month = jul,
url = "https://jlibovicky.github.io/2024/07/23/Lessons-from-multilingual-encoder",
note = "Online, Accessed: 05.06. 2026"
}