 Jindřich's blog
Jindřich's blog


Why don't people use character-level MT? – One year later
In this post, I comment on our (i.e., myself, Helmut Schmid and Alex Fraser) year-old paper “Why don’t people use character-level machine translation,” published in Findings of ACL 2022. Here, I will (besides briefly summarizing the paper’s main message) mostly comment on what I learned while working on the one-year-later perspective, focusing more on what I would do differently now. If you are interested in the exact research content, read the paper or watch a 5-minute presentation.
Paper TL;DR
Doing character-level MT is mostly not a good idea. The systems are slow, and they do not have better translation quality. Stuff that used to work on par with subwords when using RNNs does not work with Transformers, and architectures that work well for encoder-only models, are not good at all for the decoder.
On character-level MT
There are quite a few papers that show promising results when using character-level segmentation for MT. It is as good as subwords, the only flaw is the speed, and it can potentially do morphology better… except that it does not. The only really positive result is a paper by Jason Lee et al. from 2017 and perhaps a 2018 RNN model by Colin Cherry et al.. Since then, plenty of stuff has dramatically improved the translation quality. We have Transformers, we use much bigger models, and we routinely use subword segmentation regularization, which improves noise-robustness. Still, there might be some advantages of using characters. One of them is that BPEs/SentencePieces are often not morphologically plausible. Sometimes, when I look at the segmentation, it seems a slight change would help improve the generalization. It made me believe that it must be possible to build a character-level system that does not suffer from this. Perhaps it is, but now I would rather bet on finding better segmentation algorithms than frequency-based heuristics. All of this, of course, holds for high-resourced languages. For less-resourced, morphologically rich languages, alternative segmentations sometimes work better (e.g., this and this).
Showing common knowledge is not as easy as it may seem

When you ask around people who do MT, they are, for good reasons, skeptical about character-level models (primarily because of efficiency). But there is nothing in the literature that would support such a claim. All papers on character-level MT claim positive results (no wonder: paper reviewing is biased toward positive results). To support this claim, which we thought was a shared knowledge in the community, we went over 145 system description papers from WTM 2018-2020 to confirm that almost no one experimented with char-level systems and those who did not have good results. Still, this is only indirect evidence, and still, I don’t know how to argue properly against objections that literature says how great characters are and still treat peer-reviewed papers as an authority.
Implementing stuff from scratch might be fun, but mostly it is not
A large part of the paper is experimenting with different neural architectures. I spent most of the time designing the two-step decoder (and tried dozens of versions that did not work at all). Most architectures for character-level encoding shrink the inputs into some latent word-like units. With Transformers, this is important for efficiency because of the quadratic memory complexity of self-attention. Moreover, characters (in alphabetic writing systems) do not mean anything in isolation, so having a separate state for each character is a luxury we cannot afford under the quadratic number of connections.
Latent word-like units are fine for the encoder, but if we want to use it on the decoder side, we need to unshrink the states somehow to get characters again. For a long time, I thought we could generate groups of characters non-autoregressively, but I never managed to make this work. In the end, a lightweight LSTM decoder generates the characters based on the latent states (which was Helmut’s idea).
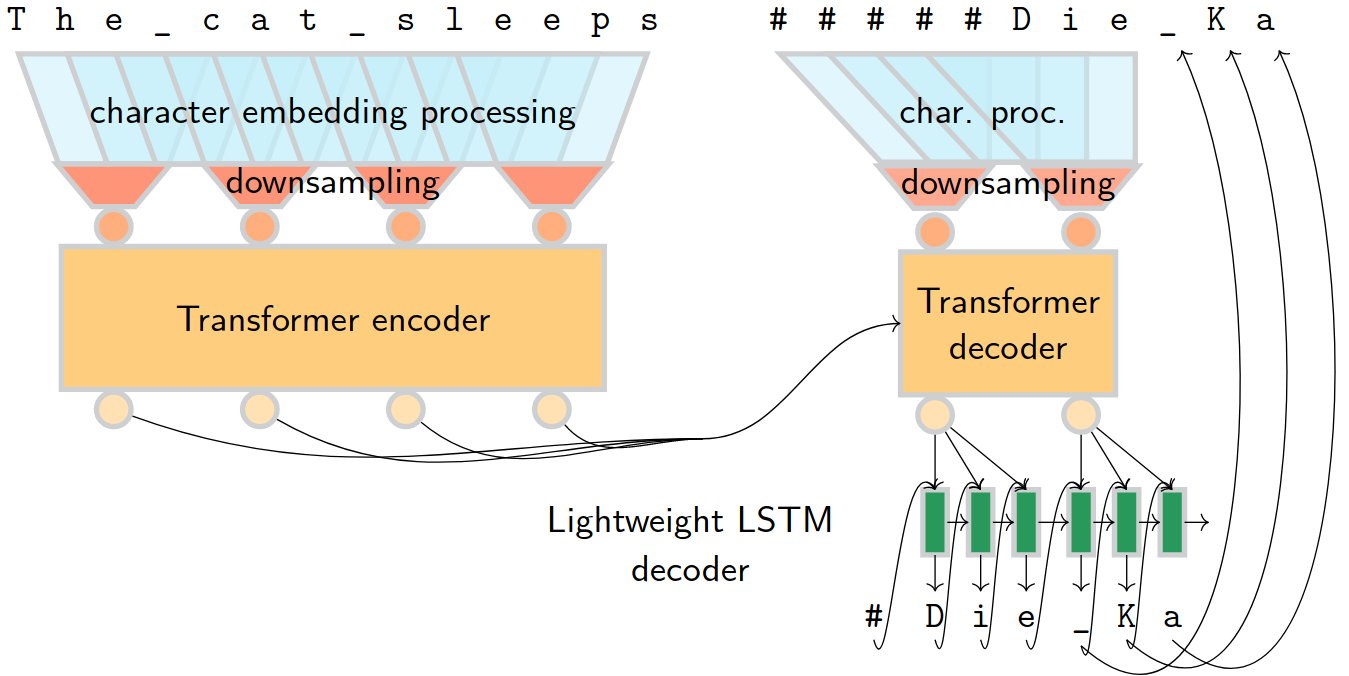
I implemented everything myself in PyTorch, thinking that I would have better control of what the decoder does. Also, it seemed that abstractions in FairSeq are first too complicated and second will bias me in thinking about the decoder. Now, I think it was not a good idea. One of my main motivations was efficiency, an issue that FairSeq folks spent a great amount of time on (and probably, therefore, the abstractions I was too lazy to understand). So there was no way I could reach the same efficiency level in my code base and could not make a fair decoding speed comparison. Given that my motivation was developing a fast architecture, it was not the greatest result. In the end, the translation quality of the two-step decoder was way worse than the vanilla decoder, so I sort of lost motivation for the efficiency comparison.
Careful evaluation takes ages, and it’s still not perfect
We tried to pay a lot of attention to evaluation: we included different domains, gender accuracy, morphological phenomena assessment, noise sensitivity, the ability to come up with novel forms and lemmas, and quality under various decoding paradigms. We did both small and large data setups – I was pretty proud of how carefully we evaluated everything. And then, when I presented a poster at ACL in Dublin, many people said: “You should have evaluated it on XY.” All were right. Besides, it is not easy to distill a comprehensive message from a huge pile of numbers – another academic skill that I did not learn.
Follow-up one year later
Based on this experience, I abandoned the topic, thinking better generalization requires better tokenization. However, at this EMNLP, I was thrilled to see Lukas Edman and other folks from Amsterdam to work on this further. In their paper, they use the two-step decoder that we proposed, with the only difference being that they do not max-pool the character hidden states using a fixed window but based on subword tokenization.
Share the post
@misc{libovicky2023blog0119,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Why don't people use character-level MT? – One year later",
year = "2023",
month = jan,
url = "https://jlibovicky.github.io/2023/01/19/Why-Dont-People-Use-Character-level-MT",
note = "Online, Accessed: 08.04. 2024"
}