 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 46: The News GPT-3 has for Machine Translation
Back in 2013, a friend of mine enthusiastically told me, how excited he was about deep learning democratizing AI (and way saying it was not relevant for NLP at all): there was no need for large CPU clusters, all you needed was buying a gaming PC and start training models and publishing ground-breaking papers. Now, it is 2020 and there is GPT-3…
Some weeks ago OpenAI published a pre-print about their giant language model that they call GPT-3. It was trained on 300 billion words, it has 175 billion parameters and it is probably the biggest artificial neural network ever trained.
This sounds cool, but there is nothing really innovative: they used the standard Transformer architecture and a lot of data, more data than anyone before, and that is it. Experiments at this scale are unavailable for most research groups in the world, so the only thing that we can do is to read how it is like when someone trains a large model and then discuss if the carbon footprint was worth it or not.
The contribution of the paper is also in how they evaluated the model. They showed that when we provide such a monstrous language model with only several examples of how to do tasks such as question answering, it can continue performing the task without any training. What the paper tries to suggest is that this is much closer to the human notion of understanding language than current machine learning approaches. After all, you do not need thousands of examples to learn how to answer questions, a few examples are usually enough.
In the rest of the post, I would like to briefly discuss what implications these results can have for machine translation.
Unsupervised translation
GPT-3 did a surprisingly good job at unsupervised machine translation. This is quite surprising given that 93% of the tokens in the training data were English words, the rest (still 21 billion words, the length 10 thousand copies of Crime and Punishment) were all other languages together. Yet after showing the model, a few examples of translation, it was able to continue translating.
Below is the table with BLEU scores with translation between three pairs of languages (Table 3.4, page 15 of the paper):
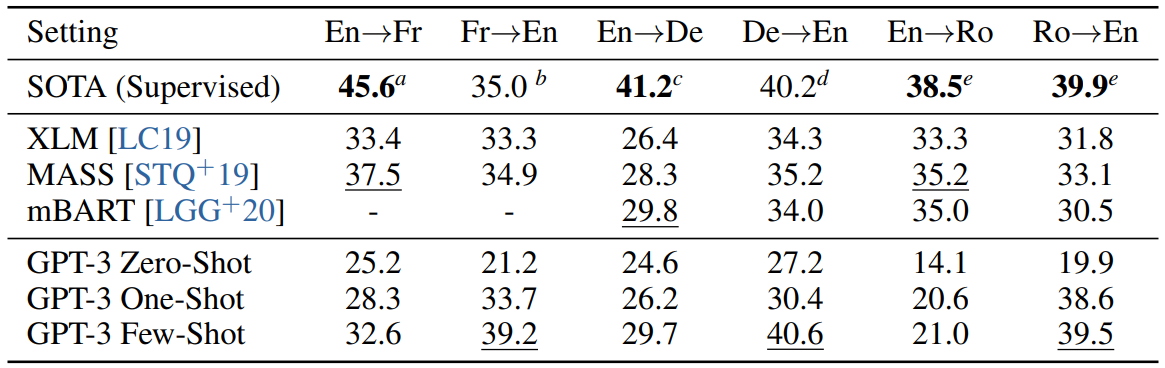
GPT-3 reaches an unsupervised state of the art in translation into English for all the three languages pairs. It seems that it almost beats the best supervised systems, but the systems they are comparing their results with are several years old. I am pretty sure that with today’s data sources and today’s modeling tricks, the best supervised systems would do much better. However, new results are only available for the newest WMT test sets which are not used for reporting the results in unsupervised MT.
In the opposite direction, translation from English, the model gets decent results, but still worse than standard unsupervised methods. My guess is that after a while of fine-training by iterative back-translation, it would do much better.
I think these results are also an interesting contribution to the discussion about what matters more: the encoder or the decoder. MT models are often explained as conditional language models. Such conceptualization attributes the primary role to the decoder, this was also reflected in the first experiments with back-translation where the authors believed that it is important to have an authentic target side. Recently several papers supported the opposite view. I discussed few of them on this blog too: forward translation can be as useful as back-translation (MT Weekly 21), probing shows that a large part of the translation process happens mostly in the encoder (MT Weekly 35), the decoder can be shallow if the encoder is deep (MT Weekly 45). GPT-3, on the other hand, seems to support a strong decoder hypothesis.
What are the consequences for unsupervised MT? Does that mean that it is solved: we just need to collect enough data, train large models, and perhaps distill them for practical deployment? Well, maybe, but what about low resource languages?
My takeaway is that the research community needs to start putting more care into underrepresented languages. These results show that large data and model size is a solution, indeed if you can get data that is large enough. Companies will find their way how to do it at a reasonable cost and develop excellent applications for languages spoken by the richest nations. There is a danger that languages of less privileged nations would stay behind and further increase the technological gap between the developed and developing nations.
Biases in the model
The authors claim that increasing the model capacity and the training data size, significantly reduces (but not at all eliminates) gender, racial and religious bias from the model predictions. I think this observation nicely matches human experience: with only limited knowledge, stereotyping might seem to have strong explanative power, whereas from a broader and more informed perspective, the harmfulness of the stereotypes suddenly becomes clearer.
I wonder if this is actually good or bad news for the field. On the one hand, it is good to know that having more data can help reduce bias. On the other hand, this might lead to apologetic arguments saying: if we had enough data, our model would not be biased. It might be true, but with a limited practical impact. GPT-3 shows that even 300 billion English words are not enough to get rid of the biases, and there are only a few languages where we can collect such a huge amount of data.
Share the post
@misc{libovicky2020blog0703,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 46: The News GPT-3 has for Machine Translation",
year = "2020",
month = jul,
url = "https://jlibovicky.github.io/2020/07/03/MT-Weekly-GPT-3",
note = "Online, Accessed: 08.04. 2024"
}