 Jindřich's blog
Jindřich's blog


Machine Translation Weekly 32: BERT in Machine Translation
I am pretty sure everyone tried to use BERT as a machine translation encoder and who says otherwise, keeps trying. Representations from BERT brought improvement in most natural language processing tasks, why would machine translation be an exception? Well, because it is not that easy.
An ICRL 2020 paper titled Incorporating BERT into Neural Machine Translation by authors from several Chinese institutions finally managed to leverage BERT in a meaningful way. Although the paper is formulated as presenting a positive result, for me the main message of the paper is that you need to try very hard to get some improvement from using BERT, and even if you do quite clever things, the improvement might pay off only specific setups.
BERT is a pre-trained model used to get contextual word representation. It is trained using the so-called masked-language-model objective. In practice, it means that 15% of the words in the sentence are masked out and the model guesses what the missing words are. To do so, it needs to somehow understand (whatever “to understand” it means) the content of the sentence and store this understanding in its hidden states. If such a model is pre-trained on millions and millions of sentences, it learns a very informative representation that can be reused in various tasks.
The paper starts with preliminary experiments with results I believe must be familiar to many research groups. If you use BERT as an encoder (no matter if with fixed weights or if you continue training it), the results are the same or even worse than when training a translation-specific encoder.
The trick with which they make it work is adding another attention layers: from the encoder to BERT and from the decoder to BERT. In this setup, the model does hot have to rely on representations from BERT, it learns its own input representation, but it can cherry-pick a useful piece of information from BERT when necessary. The architecture is shown in Figure 1 on page 4 of the paper:
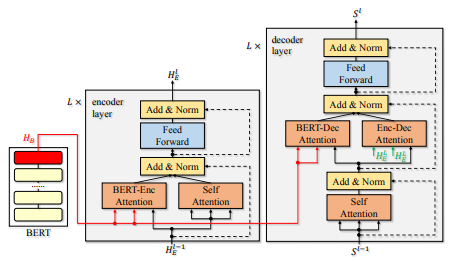
At the expense of running one extra encoder (the model is thus one third larger), this trick only negligibly improves translation between English and French. However, they do not show if it is thanks to BERT and not just because of having a much larger model. It offers some improvements for low-resource setups. Nevertheless, they only show experiments with European languages, so the question is how it would perform for really low-resource languages. The trick brings a pretty decent improvement for unsupervised translation, but the same objection holds here. If you have enough data to train BERT, it is very unlikely that you do not have any parallel data at all. Also, it might be better to use the data to train the actual translation instead of training BERT. It is not clear if it is BERT and its masked-language-model objective or the data BERT was trained on that makes the difference here.
A conclusion that I am tempted to draw is: if BERT is the only encoder you have, some information is missing, but if it just an additional source of information, it can have something that the encoder is not able to learn. If it is only due to BERT having access to plenty of training data or something else, however, remains a mystery.
For me, the main message of the paper is: meaningfully using BERT in machine translation is difficult and it is not clear if it pays off. However, for someone who would like to build a translation system between a high-resourced and a low-resourced language and there already was a well-trained BERT for the high-resource language, this might actually be a good trick to know about.
Share the post
@misc{libovicky2020blog0305,
author = "Jindřich Libovický",
title = "Jindřich's Blog -- Machine Translation Weekly 32: BERT in Machine Translation",
year = "2020",
month = mar,
url = "https://jlibovicky.github.io/2020/03/05/MT-Weekly-BERT-for-MT",
note = "Online, Accessed: 08.04. 2024"
}